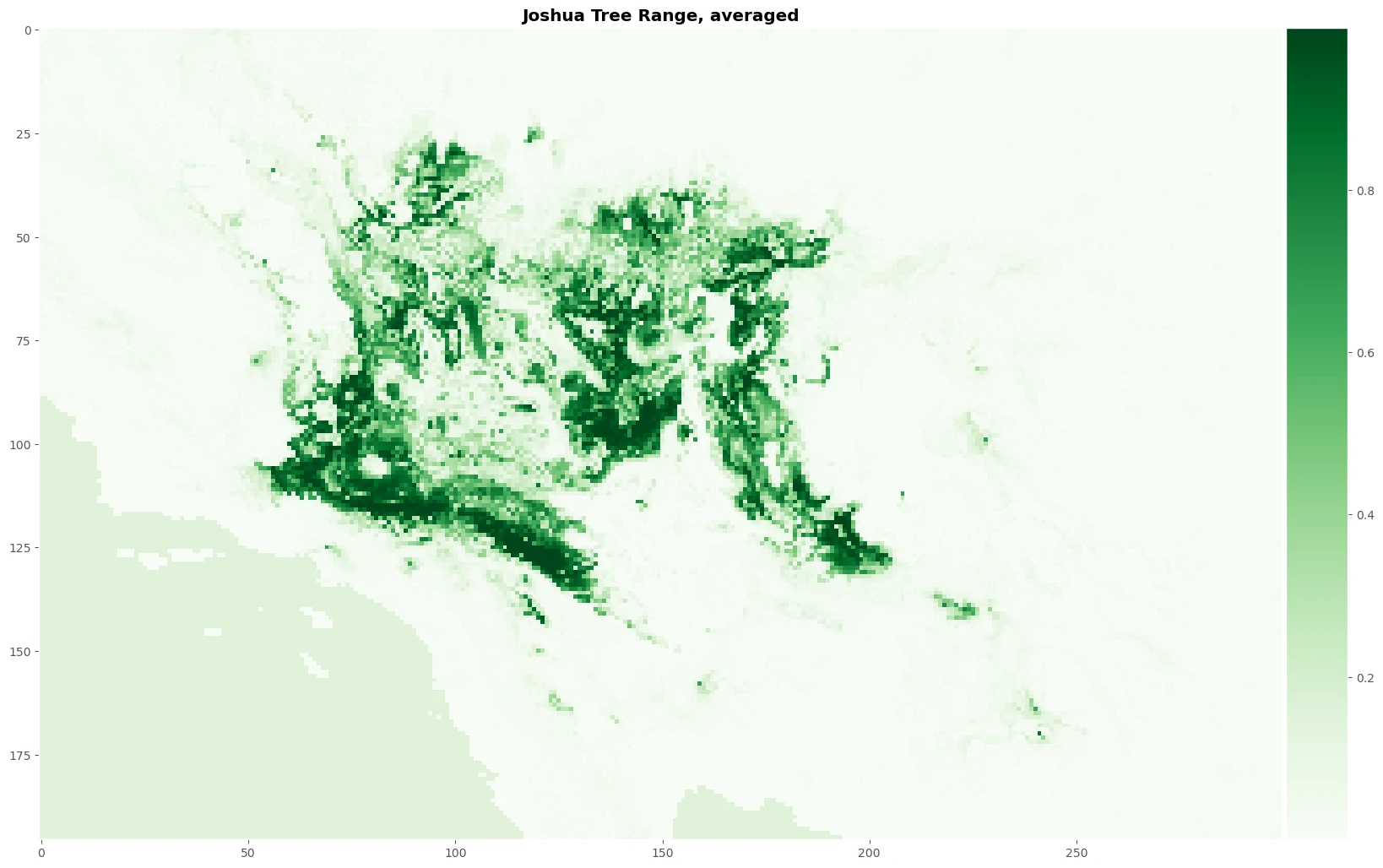
Species Distribution Modeling (SDMs) with Machine Learning
geospatial
map
distribution models
Understanding Species Distribution Models (SDMs)
SDMs are invaluable tools for:
- Ecologists tracking biodiversity changes.
- Agricultural scientists predicting pest outbreaks.
- Conservation biologists identifying priority areas for habitat protection.
- Land-use planners ensuring sustainable development that minimizes ecological impact.
With the growing availability of high-resolution geospatial and climate data, SDMs have become more powerful and accessible than ever—especially with machine learning techniques that enhance prediction accuracy. This page explores a practical SDM workflow using Python and Scikit-Learn, demonstrating how data-driven modeling can map species suitability across landscapes and inform environmental decision-making.
How SDMs Work: Linking Species to Their Environment
At the core of SDMs is a simple yet powerful idea:
Species distributions are shaped by environmental conditions.
By analyzing where a species has been observed and linking those locations to climate, land cover, and other ecological variables, we can model the species’ environmental preferences. This allows us to:
- Identify suitable habitats for species based on existing data.
- Predict new locations where the species might thrive.
- Forecast changes in species distributions under different climate scenarios.
Key Steps in an SDM Workflow
- Conceptualization – Define the research question and species of interest.
- Data Pre-processing – Collect and clean occurrence records and environmental data.
- Model Training & Assessment – Use machine learning (e.g., Scikit-Learn classifiers) to establish species-environment relationships.
- Interpolate & Extrapolate – Apply the model to predict species distribution across space and time.
- Iteration – Refine the model based on new data or improved techniques.
Interpolation vs. Extrapolation: Mapping Species Distributions
Once an SDM is trained, it can be used in two main ways:
-
Interpolation: Mapping species suitability within the same geographic area and environmental conditions used to train the model. This helps identify potential habitats based on known environmental relationships.
-
Extrapolation: Applying the model to new areas or future climate scenarios. This is crucial for predicting how species distributions might shift due to climate change, habitat loss, or human interventions.
By utilizing machine learning, SDMs can process large datasets efficiently and generate highly accurate habitat suitability maps, making them essential tools for modern conservation and ecological research.
Why This Matters
- Biodiversity Conservation – Helps identify critical habitats and inform conservation planning.
- Climate Change Adaptation – Predicts how species might shift in response to changing temperatures and precipitation.
- Invasive Species Management – Identifies areas vulnerable to the spread of non-native species.
- Agriculture & Pest Control – Anticipates crop pest distributions under different environmental conditions.
Whether you’re an ecologist, a data scientist, or just an enthusiast in geospatial sciences, understanding SDMs opens doors to data-driven insights into species-environment interactions.