How to improve Deep Learning result?
Deep Learning
Machine Learning
optimization
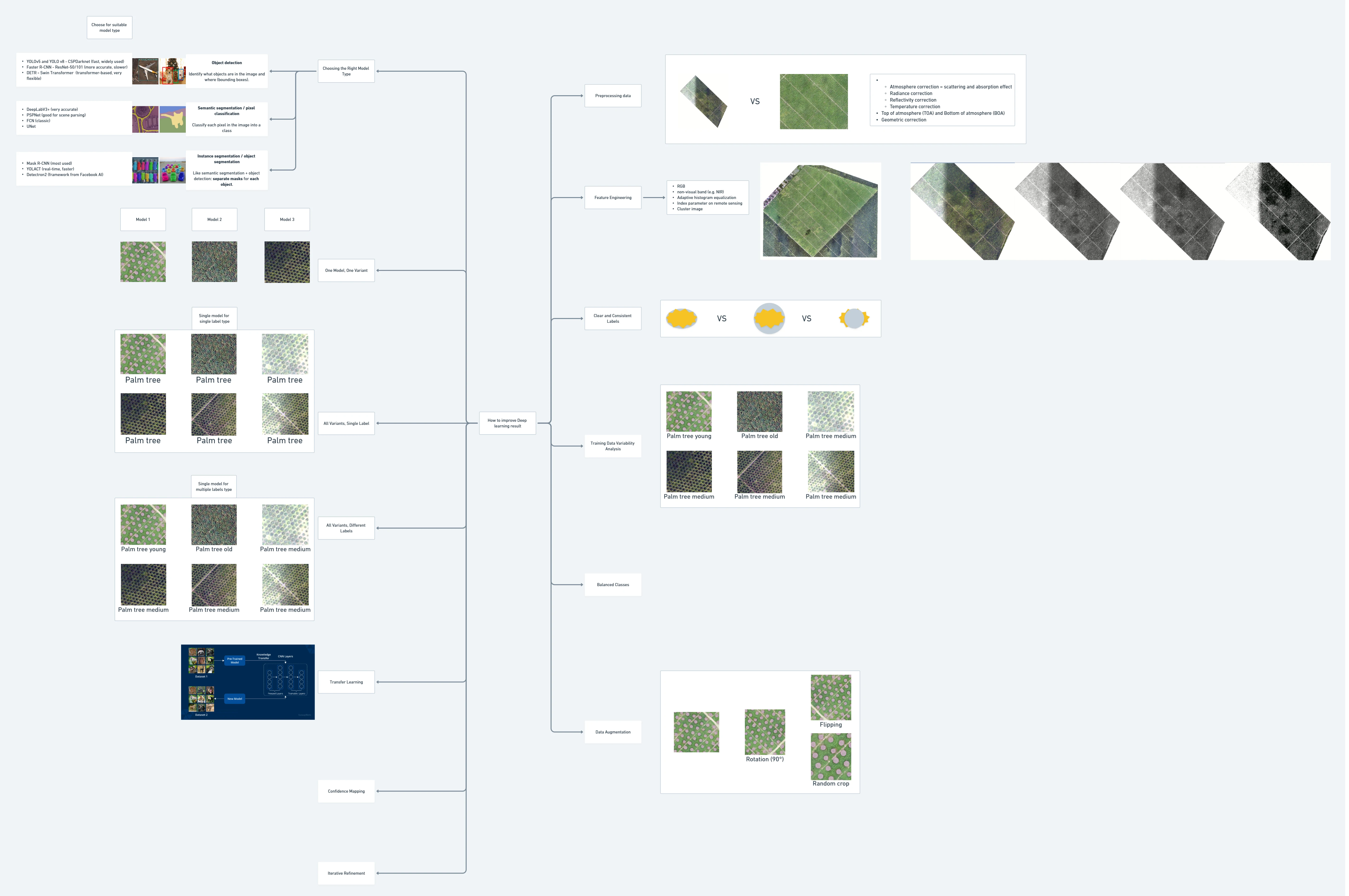
To unlock high-accuracy models in geospatial AI, we must look beyond just training. A successful model is built on solid preparation—from data preprocessing to smart label design and model selection. In This page, we will introduce some techniques how to improve our Deep Learning result from end-to-end process. Additionally, we will also discuss about How to measure the detected object? especially for round objects from remote sensing such as palm tree.
Simple Deep Learning Development
Preprocessing
Data quality of input data sets the ceiling for model performance. Preprocessing ensures our imagery is clean, consistent, and focused before training. Especially important when training on remote sensing imagery with varying acquisition conditions.

Examples:
- Normalize imagery (e.g., same resolution, scale, CRS).
- Remove irrelevant information (clouds, shadows, no-data areas).
- Clip and tile imagery for manageable input sizes (e.g., 256x256, 512x512).
- Apply feature engineering, such as smoothing, sharpening, or color corrections if needed.
- Radiometric correction
Feature Engineering – Elevating Model Understanding
Raw RGB imagery often isn’t enough. Feature engineering gives our model more context. By incorporating additional bands, we help the model focus on traits that separate we target object from its background. More meaningful features lead to more onfident predictions.

Examples:
- Adding vegetation indices or terrain-derived layers (NDVI, GNDVI as extra channels) to better highlight objects like trees, water, or buildings.
- Derive texture metrics using focal statistics, histogram equalization, clustering pixel image or edge detection.
- Add non-visual band (e.g. NIR)
2 Geoprocessing tools that we can use in ArcGIS Pro namely:
-
Iso Cluster Unsupervised Classification: Performs unsupervised classification on a series of input raster bands using the Iso Cluster and Maximum Likelihood Classification tools.
-
Segment Mean Shift: Groups adjacent pixels that have similar spectral characteristics into segments. Each output raster from above tools can be combine with original raster using
CompositeBandstools.
Choosing the Right Model Type
- Object detection
Object detection is the process of locating features in an image. The model be able to detect the location of different objects. This process typically involves drawing a bounding box around the features of interest.

- Semantic segmentation
Semantic segmentation occurs when each pixel in an image is classified as belonging to a class. In GIS, this is often referred to as pixel classification, image segmentation, or image classification.
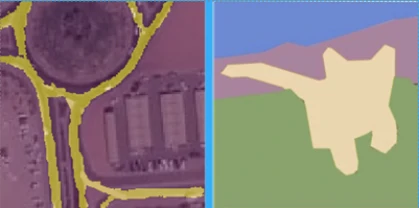
- Instance segmentation
Instance segmentation is a more precise object detection method in which the boundary of each object instance is drawn. This type of deep learning application is also known as object segmentation.

Different deep learning tasks solve different problems. Choosing the right model type ensures we’re solving ours efficiently. ArcGIS supports various deep learning models—U-Net, Mask R-CNN, and YOLO—each with strengths depending on our task. Choosing the right backbone, like ResNet or MobileNet, lets we balance performance with processing speed.
Examples:
- Object Detection (YOLO, Faster R-CNN): Output = bounding boxes.
- Semantic Segmentation (U-Net, DeepLab): Output = class per pixel.
- Instance Segmentation (Mask R-CNN): Output = individual object masks.
In example for each model type:
- Object detection
- Semantic segmentation
- Instance segmentation
Training Data Variability Analysis
Before labeling or training, we need to visually analyze the diversity of the objects and environments across the imagery. This helps ensure the model sees enough variation to generalize.

Examples:
- Examine imagery across regions and time
- Identify intra-class variability: object size, shape, orientation, illumination, background complexity.
- Palm trees may look different in highland vs lowland terrain or on different soil types.
- Use Export Training Data for Deep Learning to sample image chips and view in a mosaic.
Clear and Consistent Labels
Even the best model will underperform if our labels are inconsistent. Avoid overlapping or ambiguous polygons. Label edges cleanly and follow class definitions strictly. This builds a reliable ground truth that the model can learn from with confidence.
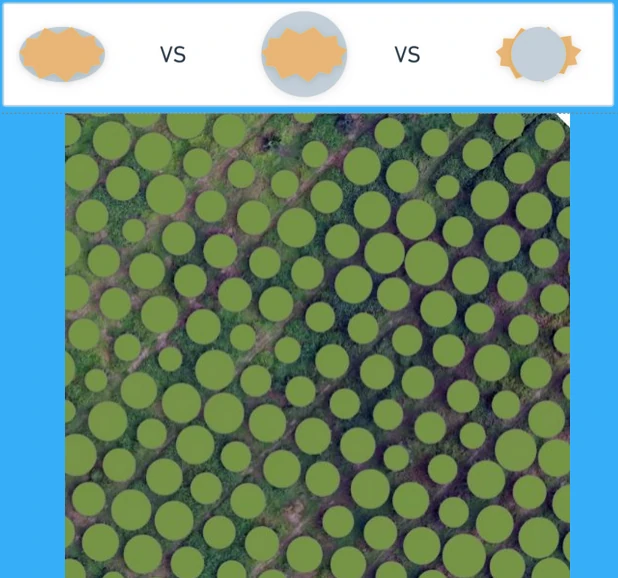
Examples:
- Avoid overlapping, duplicated, or imprecise labels.
- Match labels to model type (bounding box for detection, polygons for segmentation).
- Keep class definitions tight and documented.
- Use Label Objects for Deep Learning, refine with Snapping, Edit Vertex, and Topology tools to maintain clean geometries.
Labeling - One Model, One Variant
When object appearances vary widely—for example, young vs mature palm trees—it’s often best to train separate models for each variant. This approach is effective for high intra-class variability.

Examples:
- Isolate object variants with distinct shapes, colors, or patterns.
- Train separate models for each variant to increase precision.
- Train one model for young palm trees and another for mature palms due to canopy shape and size differences.
- Use separate folders for each model’s training dataset.
Labeling - All Variants, Single Label
If our task doesn’t require distinguishing between subtypes, combining variants under one label simplifies training and deployment. This reduces labeling complexity and model size. But this also reduce accuracy and precision.

Examples:
- Merges all object appearances into a single class.
- All types of palm trees are labeled as one class for simple plantation mapping.
- Set all labels to a single class code (e.g.,
palm_tree = 1) during Export Training Data for Deep Learning. Use fewer classes to reduce training complexity.
Labeling - All Variants, Different Labels
When classifying object subtypes matters, each variant needs its own label. This enables the model to differentiate with greater detail. This helps the model distinguish fine-grained differences and adds classification value to your output.

Examples:
- Label each subtype:
palm_tree,palm_tree_medium, andpalm_tree_crowded. - Include a class_value attribute in the label dataset. Use multi-class detection or segmentation during training by setting class mapping
Importance of Including All Variability
A model can only learn what it has seen. If key variations are missing from the training data, even the best architecture will fail to generalize.

Examples:
- Include edge cases: occlusions, different orientations, partial shadows.
- Avoid over-representation from one scene (e.g., all samples from the same plantation).
- Stratified sampling by region, types, and ages type before labeling.
Transfer Learning
Transfer learning allows you to stand on the shoulders of giants. Start with a pretrained model and fine-tune it to your data. In ArcGIS, we can load a pretrained model and fine-tune it to your specific dataset.
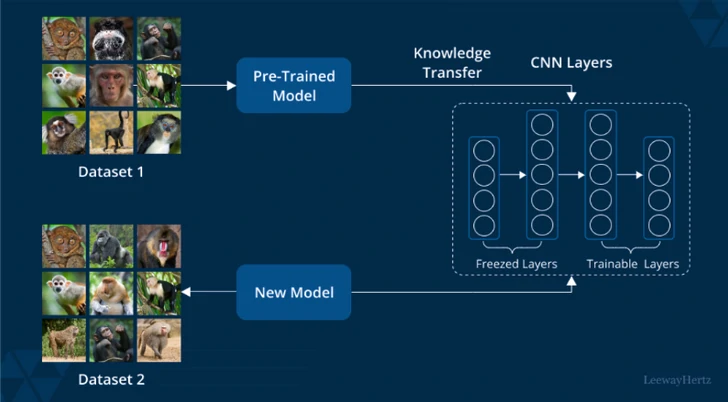
Example:
- Use multiple milestones (e.g. difference labels type, difference region) that train and evaluate single model for each milestone use pretrained weights from previous milestone.
- Use Train Deep Learning Model with
pretrained_modelparameter to load them.
Additional Best Practices
Beyond those techniques, a few small strategies can make a big difference in model reliability and real-world performance
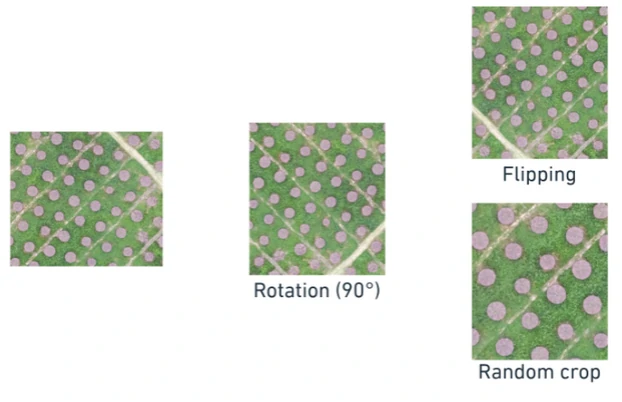
Examples:
- Use data augmentation: rotation, flips, noise, brightness.
- Retrain iteratively after error analysis (e.g. add more training samples from misses objects, and retrain.)
- Visualize confidence maps to spot uncertain predictions. Turn on
confidence raster outputin Classify Pixels Using Deep Learning or Detect Objects Using Deep Learning. Use it in error inspection workflows.
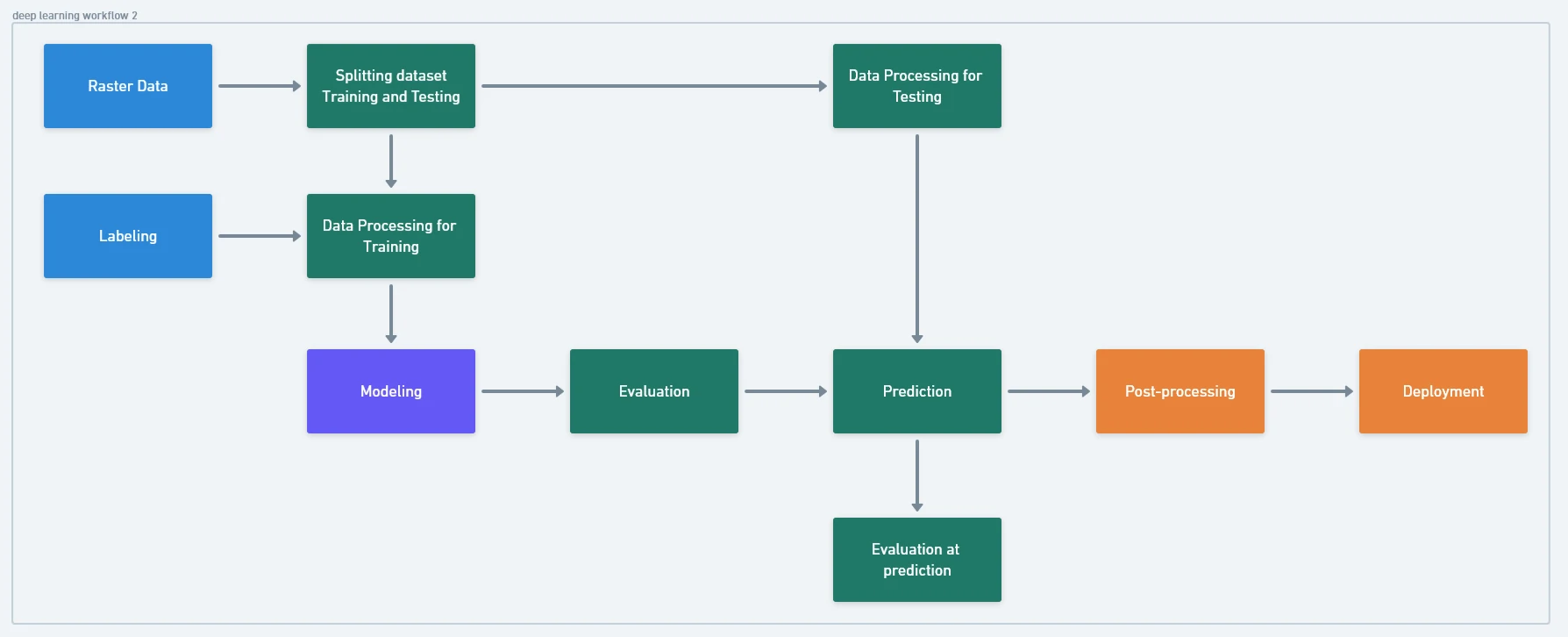
How to Optimize Our Inference Process
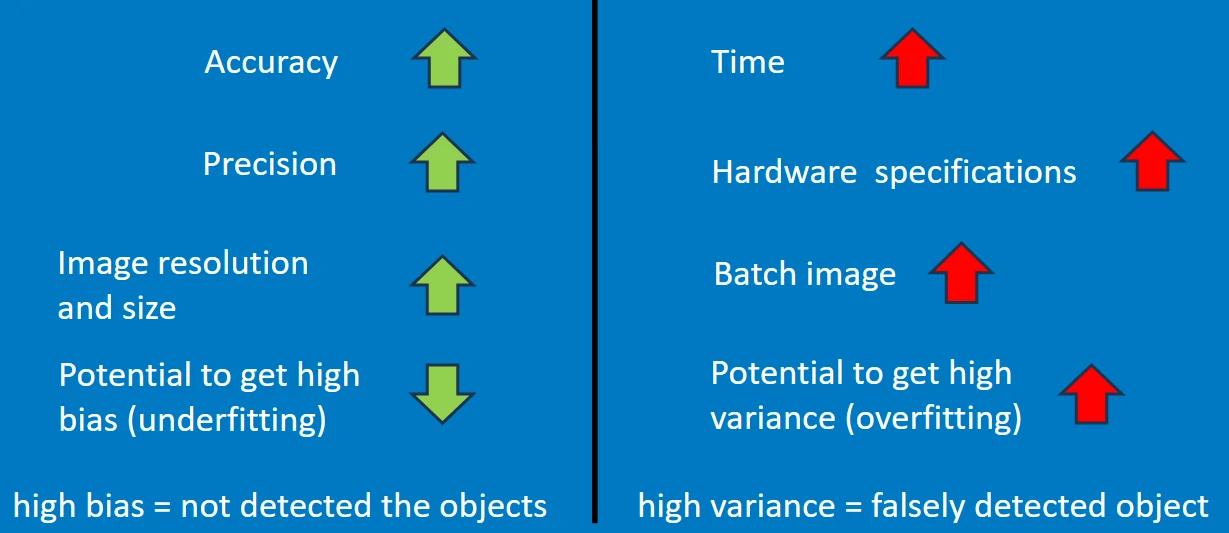
The processing time for deep learning in ArcGIS depends on several key factors:
- Tile size or image resolution used during both training and inference.
- Hardware specifications of the device in use.
- GPU capabilities (e.g., VRAM size, processing speed).
- Disk read/write performance.
- Selected model architecture and backbone (e.g., ResNet, MobileNet).
- Batch size settings for prediction and training.
- Concurrent system load, such as other applications running alongside ArcGIS Pro.

Example Performance Metrics (Using NVIDIA RTX A2000 12GB ≈ RTX 3060):
- Object Detection
- Training: ≈ 2 – 3 hours.
-
Inference: ≈ 30 minutes to 1 hour.
- Semantic or Instance Segmentation
- Training: ≈ 1 – 2 days.
- Inference: ≈ 2 – 3 hours.
Trade-Off between Cost vs Quality
Model Limitations & Failure Zones
Even with strong training, deep learning models can fail—especially in unseen conditions. Knowing where and why this happens is key to improvement.
 20
20
Examples:
- Causes: unseen backgrounds, poor lighting, extreme object deformation.
- Visualize errors using prediction overlays and confidence maps.
- Flag and relabel failure zones for retraining (closed feedback loop) and to guide future labeling.
Final and Complete Deep Learning Development
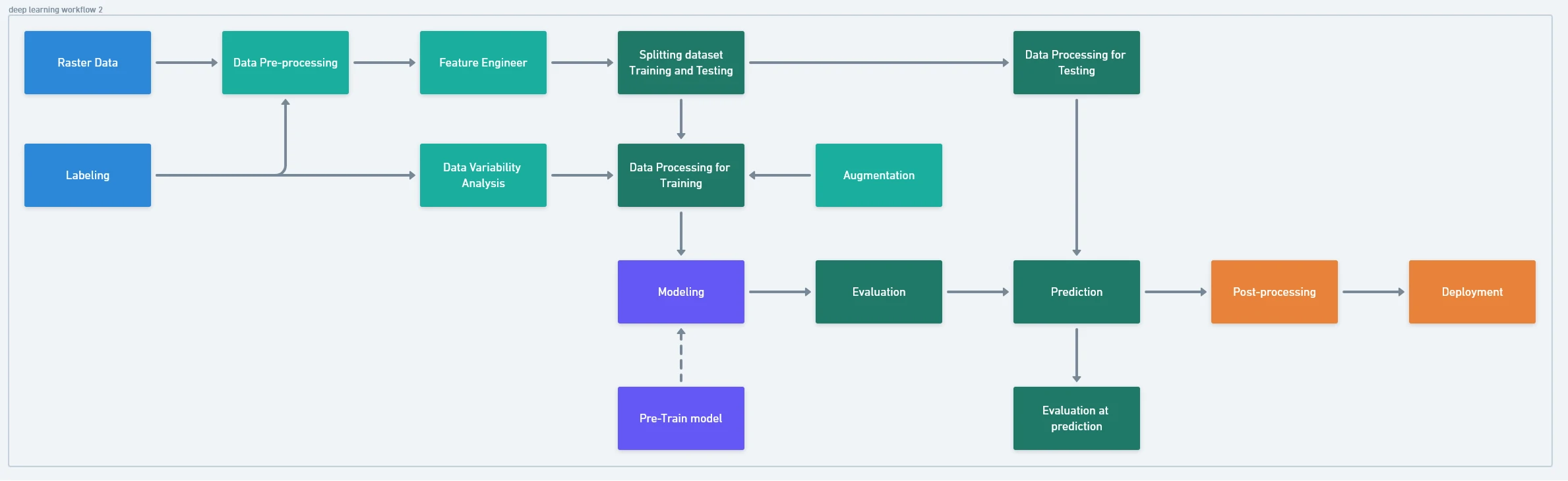
How to measure the detected object?
-
Using Minimum Bounding Geometry Creates a feature class containing polygons which represent a specified minimum bounding geometry enclosing each input feature or each group of input features.
-
Using custom script:
- Calculate boundary area coverage
- Measure the center point of boundary area
- Measure the radius from the area (radius = math.sqrt(area / pi))
- Utilize buffer with center point and radius to create circle
Final Thoughts
By applying structured practices—clear labeling, preprocessing, feature engineering, and leveraging transfer learning—we turn GIS deep learning from experimental to production-ready. The ArcGIS ecosystem gives us the full pipeline to do this efficiently.
Deep learning in GIS is both art and science. It takes thoughtful preparation, the right tooling in ArcGIS, and iterative refinement. With these principles, your model’s performance will go beyond expectations.