Pipeline Design Patterns 101
data engineering
data modeling
pipeline
design patterns
What Are Data Pipelines?
A data pipeline is a system that moves, processes, and transforms data throughout its lifecycle. It begins where data is generated (e.g., databases, APIs, streaming platforms, or flat files) and concludes with data stored in warehouses, processed in machine learning models, or analysed for insights.
Key Design Patterns in Data Pipeline Architecture
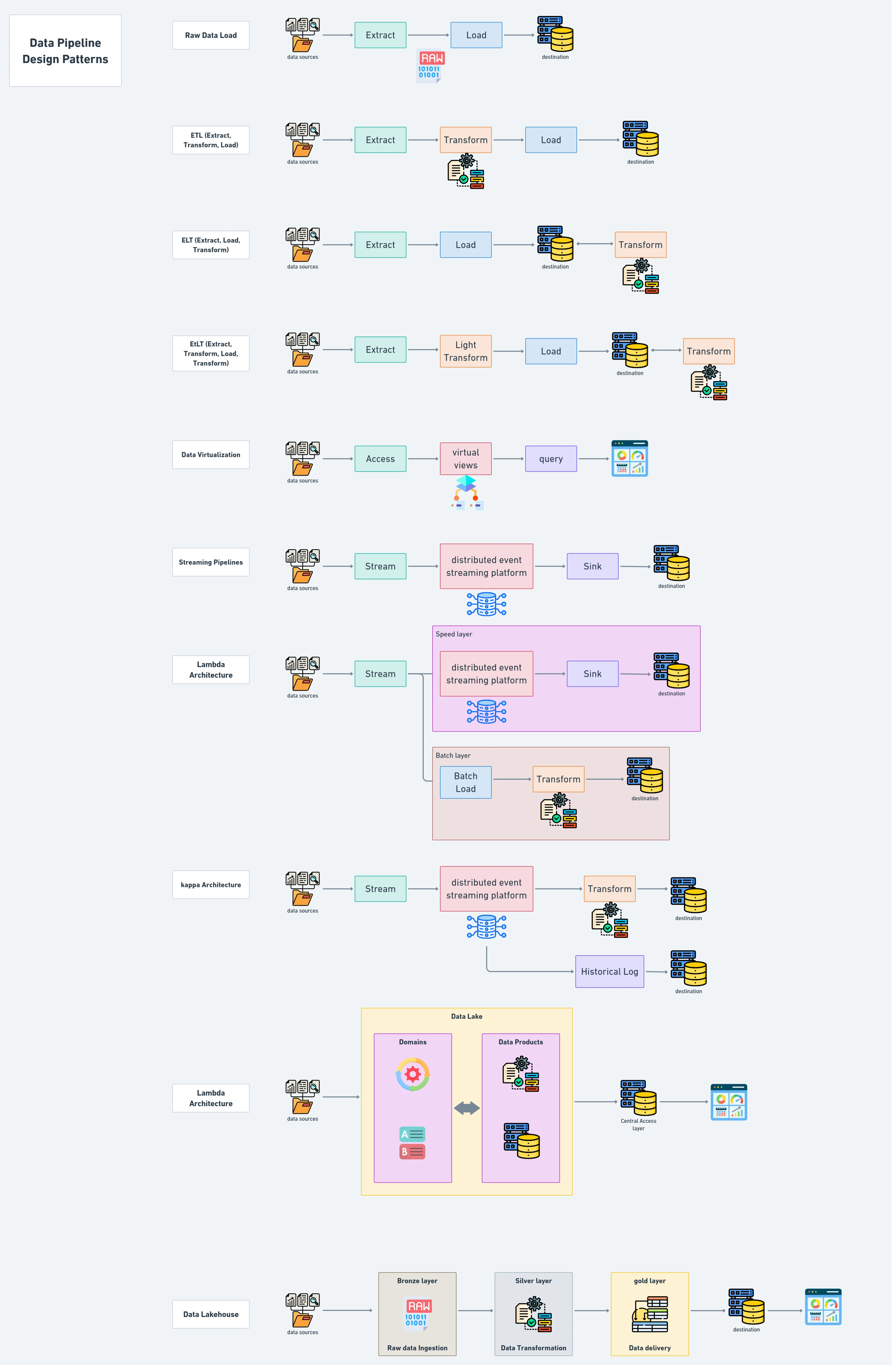
Raw Data Load
- Purpose: Transfers unprocessed data between systems, often for bulk migrations or initial loading of databases.
- Method: Moves raw data directly from the source to the target system.
- Benefits:
- Simplifies one-time operations like database migrations.
- Handles large data volumes efficiently.
- Limitations: Unsuitable for ongoing operations or use cases requiring cleaned or structured data.
ETL (Extract, Transform, Load)
- Purpose: Processes structured and semi-structured data with complex transformation requirements for analytics or integration.
- Method: Extracts data from sources, transforms it (e.g., cleansing, standardisation), and loads it into the target system.
- Benefits:
- Ensures data quality and consistency for downstream applications.
- Handles integration from multiple sources effectively.
- Limitations: Batch-oriented, resulting in built-in latency and delayed availability of data.

ELT (Extract, Load, Transform)
- Purpose: Accelerates data availability by loading raw data into the target system before applying transformations.
- Method: Extracts data, loads it into a storage like datalake to datalakehouse, and performs transformations in place.
- Benefits:
- Reduces initial latency by enabling immediate access to raw data.
- Leverages the computational power of modern data warehouses.
- Limitations: Exposes unprocessed data to users, which may result in data quality or privacy concerns.
EtLT (Extract, Transform, Load, Transform)
- Purpose: Combines fast availability with initial data cleaning and post-load transformations.
- Method: Performs lightweight transformations during extraction (e.g., cleansing, masking), loads the data, and completes advanced transformations in the target system.
- Benefits:
- Balances rapid data availability with data integrity and privacy.
- Handles multi-source integration after initial transformation.
- Limitations: Requires managing both pre-load and post-load transformation stages.

Data Virtualisation
- Purpose: Provides on-demand data access by creating virtual views without physical duplication.
- Method: Integrates and transforms data dynamically through query-driven processes, leveraging abstraction layers.
- Benefits:
- Avoids data replication, reducing storage costs.
- Offers up-to-date data without requiring scheduled processes.
- Limitations:
- Performance depends on the structure and indexing of the underlying data sources, which can impact query efficiency.
- Limited functionality compared to ETL or ELT, making it less suitable for complex transformations or advanced analytics.
- Its read-only nature restricts data manipulation capabilities.

Streaming Pipelines
- Purpose: Processes and delivers data in real-time, ensuring continuous updates for systems or applications.
- Method: Ingests data from streaming platforms (e.g., Kafka, Kinesis) and processes it in motion without delays.
- Benefits:
- Provides low-latency insights for real-time decision-making.
- Ensures smooth handling of high-frequency, continuous data streams.
- Limitations: Requires specialised tools and infrastructure for stream processing and may involve higher costs than batch pipelines.

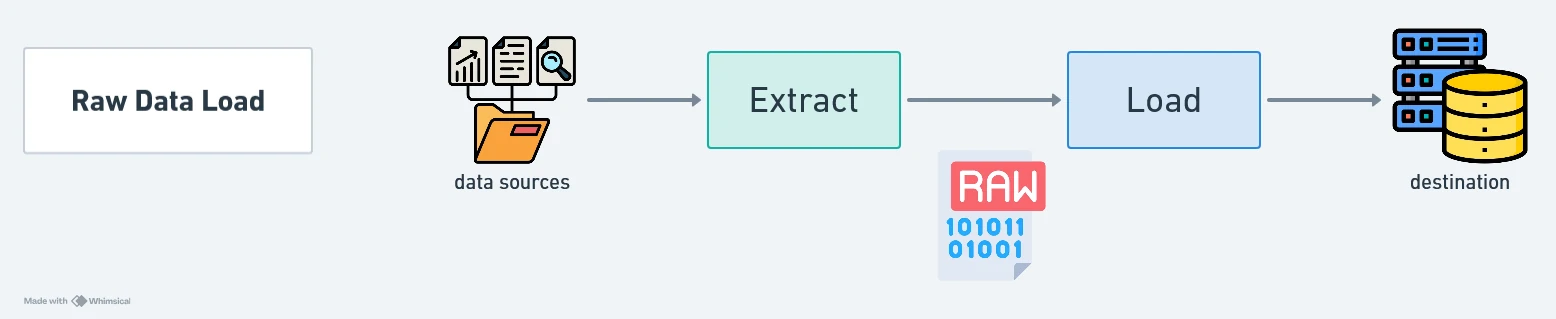
Lambda Architecture
- Purpose: Combines batch and stream processing to achieve both real-time updates and batch accuracy.
- Method: Divides processing into two layers:
- Batch Layer: Processes historical data for accuracy and completeness.
- Speed Layer: Processes real-time data for low-latency insights.
- Benefits:
- Provides a balance between real-time updates and historical data.
- Simultaneous handling of high-latency and low-latency use cases.
- Limitations: Increases complexity and operational overhead.

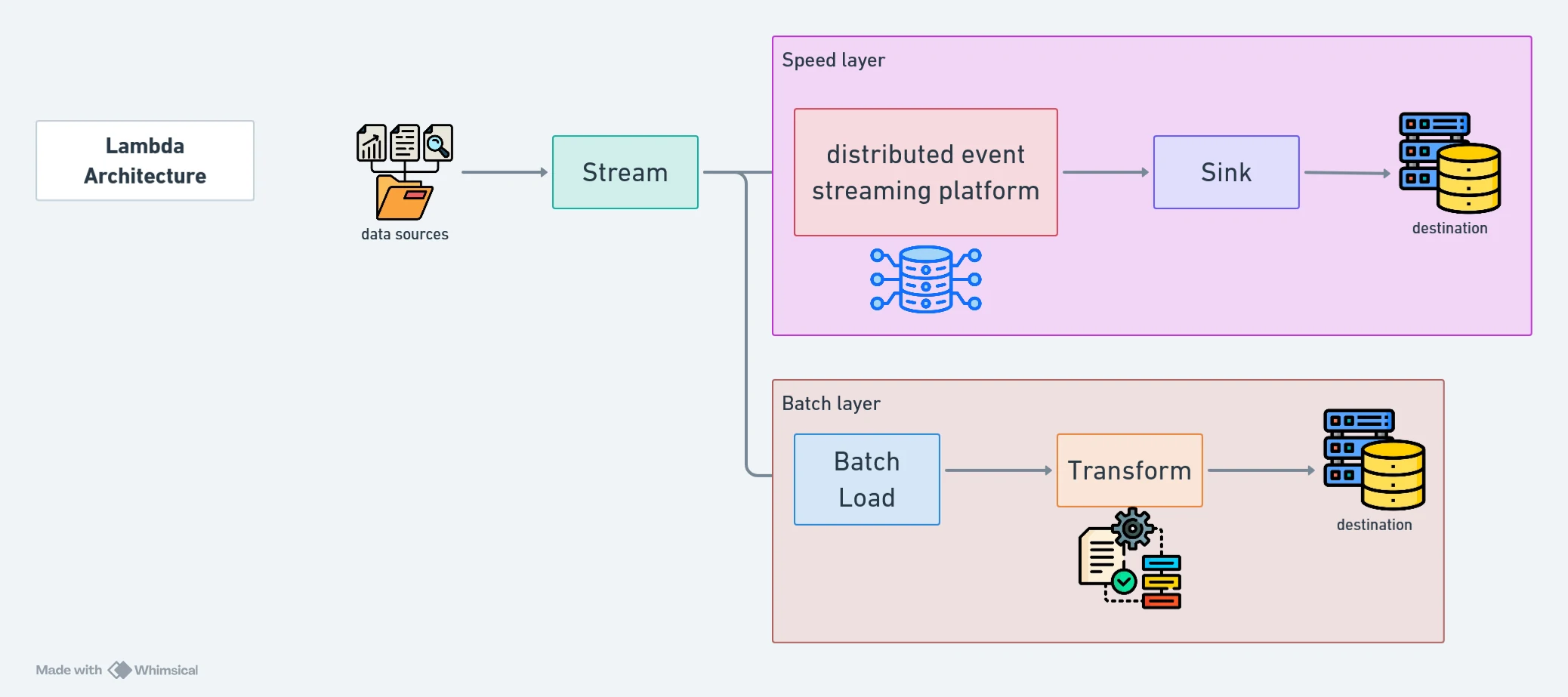
Kappa Architecture:
- Purpose: Simplifies data processing by eliminating the batch layer and relying solely on streaming with historical data replay.
- Method: Utilises a single stream processing system capable of handling both real-time and historical data through replayable streams.
- Benefits:
- Reduces complexity by unifying processing layers.
- Offers flexibility with replay capabilities for historical data.
- Limitations: Depends on a robust and scalable stream processing system.
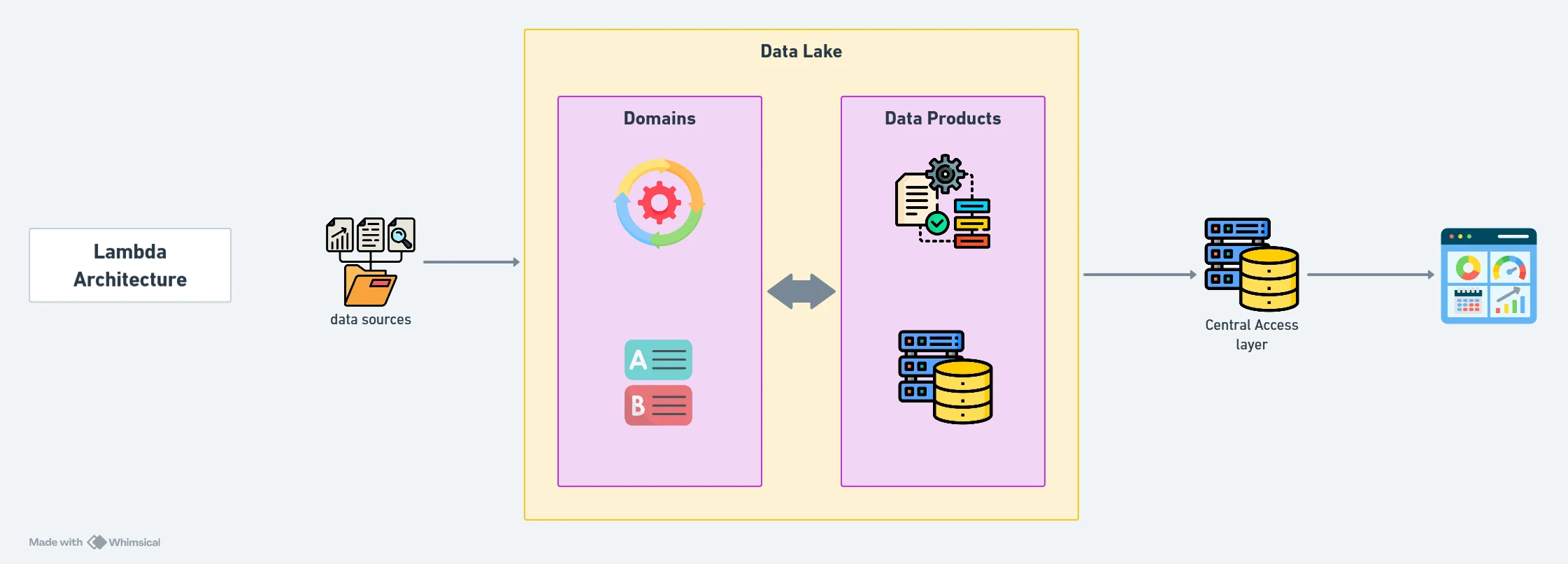
Data Mesh (Decoupled Architecture):
- Purpose: Supports decentralised teams with autonomy while maintaining centralised governance and discoverability.
- Method: Raw data is stored in a shared data lake using open formats (e.g., Parquet), and teams process it independently into analysis-ready datasets.
- Benefits:
- Allows teams to use their preferred tools and workflows.
- Ensures consistent data standards across the organisation.
- Limitations: Relies on robust governance frameworks and consistent cataloguing practices.
Data Lakehouse:
- Purpose: Blends the structured querying capabilities of data warehouses with the flexibility and scalability of data lakes.
- Method: Organises data into three layers:
- Bronze Layer: Stores raw data in its original form.
- Silver Layer: Cleansed and validated data ready for further analysis.
- Gold Layer: Analytics-ready data refined for specific business use cases.
- Benefits:
- Provides unified analytics across structured and semi-structured data.
- Reduces duplication by combining data lake and warehouse capabilities.
- Limitations: Requires careful management of data across the three layers to avoid inconsistencies and inefficiencies.
Challenges and Trends in Data Pipelines
Modern pipelines face growing complexity with increasing data volumes, diverse formats, and real-time requirements. Key challenges and trends include:
- Balancing Agility and Governance: Seen in the rise of Data Mesh, which supports decentralised processing with centralised oversight.
- Bridging Batch and Real-Time Paradigms: Achieved through patterns like Lambda Architecture and Kappa Architecture.
- Managing Complexity in Multi-Layered Architectures: Lakehouse approaches require careful coordination across layers (Bronze, Silver, Gold) to maintain data consistency and avoid duplication.