Scoring
Recommendation
Optimization
matchmaking
Overview
To generate score and rank the generated candidates in order to select a set of items to present to the user, the system may utilize multiple candidate generators that draw from different sources, such as:
- Related items from a matrix factorization model. The matrix is factorized into two matrices and their dot product generates a score for each user-item pair:
- the representing users (interaction, transaction)
- the representing items
- User-specific features for personalization.
- User’s profiles
- User’s preference
- Geographic information for considering “local” versus “distant” items
- Popular or trending items. This approach recommends items that are currently popular or trending based on factors such as sales, views, or social media activity.
- Social graph data that considers items liked or recommended by friends. This approach uses the social connections of the user to identify items that are recommended or liked by the user’s friends or social network.
Methods and Techniques for Scoring
- Cosine Similarity
- A common similarity measure the similarity between the features of items and user preferences.
- Weighted Average Score
- Weighted average is a method of calculating a single score for a set of items, where each item is assigned a weight based on its importance and so, this means that items that are more relevant to the user should have a higher weight in the calculation of the final score.
- Factorization Machines
- A popular algorithm for scoring that models interactions between features and allows for non-linear relationships.
- A machine learning model that can capture the interactions between users and items in a latent space. It uses matrix factorization to represent users and items as low-dimensional vectors and then applies a linear model to these vectors to predict the rating or preference score.
- Neural network
- Can learn complex representations of user preferences and item features. this representation can be from textual or visual features of items, and/or user-item interactions directly.
Case for Instagram filtering approach
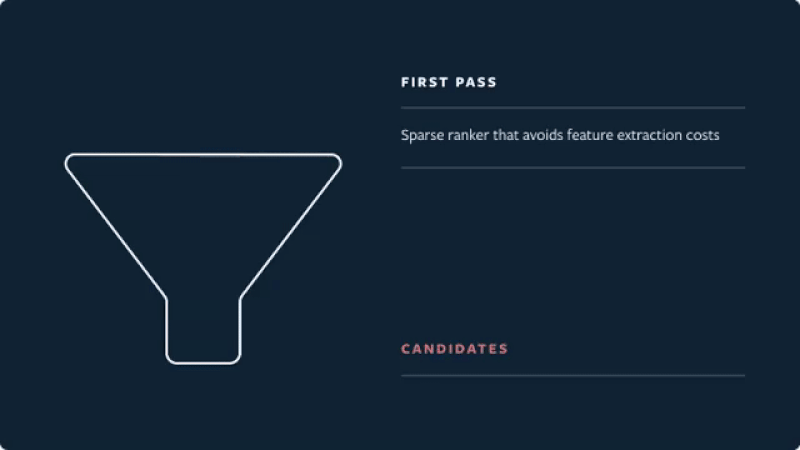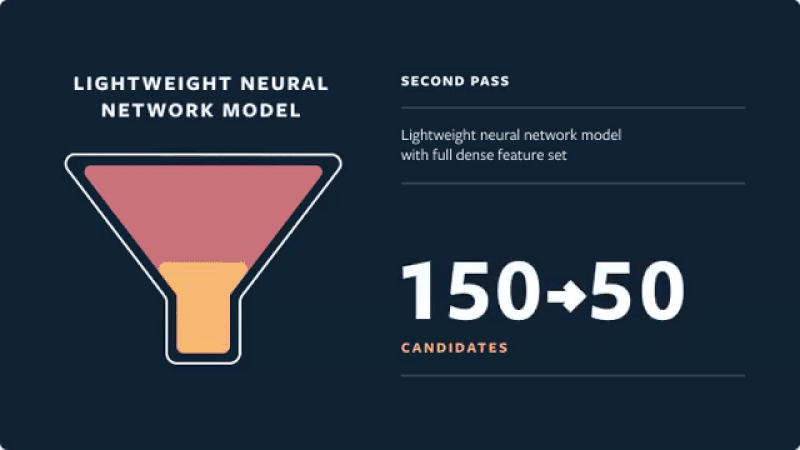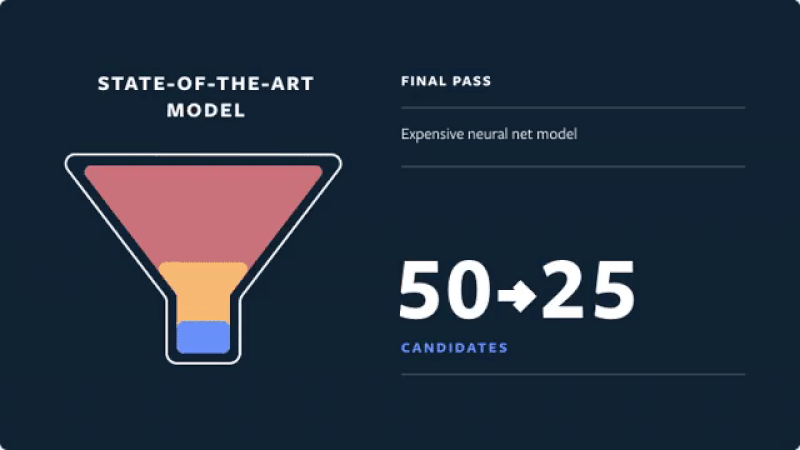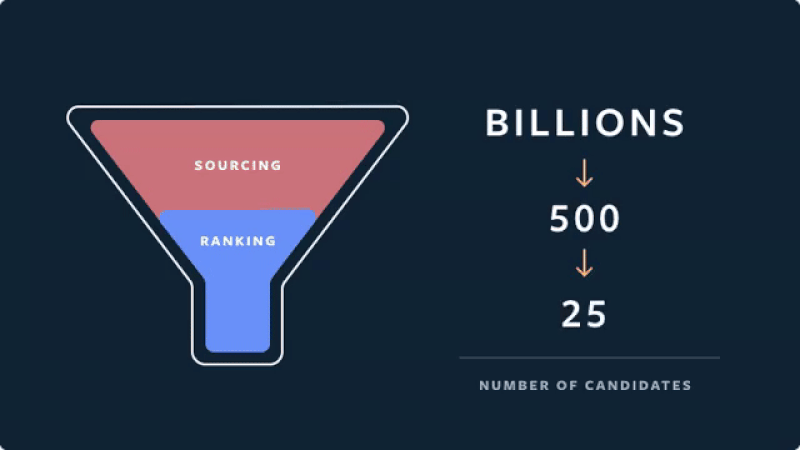
- Candidate generation stage
- Sampling 500 item candidates
- Through a three-pass ranking process which uses a combination of techniques to shrink neural network models:
- First pass: A distilled model mimics the later stages with minimal features to return the top 150 ranked candidates.
- Second pass: A lightweight neural network uses the full set of dense features and returns the top 50 ranked candidates.
- Final pass: A deep neural network uses the full set of dense and sparse features to return the top 25 ranked candidates (for the first page of the Explore grid).
Candidate Ranking / Learning to Rank (LTR)
- Learning to Rank (LTR) problem: involves selecting the most relevant items from the pool of candidate items to present to the user.
- Ranking can be done over multiple stages, such as:
- Simplest dual-stage scenario, the typo stages may be called coarse and fine ranking.
- Multi-armed bandits
- Wide-and-deep networks
Goal
- Aim to predict the probability that a user will interact with an item, given their previous interactions and other contextual information.
LTR Categories
-
LTR methods can be classified into three categories:
Technique Point Wise Pair Wise List Wise Recommender RankNet ✅ ❌ ✅ ✅ Collaborative LambdaRank ❌ ✅ ✅ ✅ Collaborative ListMLE ❌ ❌ ✅ ✅ Collaborative NDCG ❌ ❌ ✅ ✅ Collaborative and Content-based SoftRank ❌ ❌ ✅ ✅ Content-based AdaRank ❌ ❌ ✅ ✅ Content-based ListNet ❌ ❌ ✅ ✅ Collaborative and Content-based Factorization Machine ❌ ❌ ✅ Collaborative hybrid
Point-wise Methods
- How
- evaluate items independently, ignoring the rank order of other items.
- These methods predict the relevance of a single item for a given query by training a classifier or regressor to score each item based on a set of features, such as those used in a linear model like logistic regression, decision trees, or neural networks depending on the complexity of the feature space and the problem.
- Models
- Logistic regression
- Logistic Regression is particularly useful when interpretability is important, as the model coefficients directly indicate the strength of each feature in determining relevance.
- Decision trees
- Gradient Boosted Decision Trees (GBDTs)
- The algorithm aims to optimize a ranking metric, such as Normalized Discounted Cumulative Gain (NDCG)
- SVM
- Maps features to a higher-dimensional space to find a hyperplane that separates relevant and irrelevant items.
- Neural network
- Logistic regression
- Result
- The final ranking is obtained by sorting the list of results based on these individual item scores.
- The relevance score assigned to each item is independent of the scores assigned to other items in the same query result set.
- These methods often employ binary or multiclass classification models, where the task is to predict the relevance label for each item in isolation relative to other items (e.g., relevant vs. non-relevant in binary classification or multiple relevance levels in multiclass settings).
- Types
- single-item
- multi-item
- Pros
- Simplicity: Easy to implement
- Flexiblity: A wide range of regression and classification algorithms can be employed, allowing the use of various features to predict relevance.
- Scalability: These methods are computationally less intensive compared to pair-wise and list-wise methods, making them suitable for large-scale applications.
- Cons
- Lack of Contextual Awareness: Ignores item-item relationship
- May lead to suboptimal ranking
- Limited Optimization: They may not capture complex dependencies or the competitive nature of items vying for the same query
Pair-wise Methods
- How
- Pair-wise methods involve comparing items in pairs, aiming to learn a function that assigns a higher score to the preferred item in each pair.
- Given a pair, the objective is to learn the optimal ordering and minimize the number of inversions, which occur when the pair’s order is incorrect relative to the ground truth. The loss function focuses on pairs of items.
- Pair-wise methods align more closely with the nature of ranking tasks, as they directly model the relative order of items.
- Pair-wise methods often employ binary classification models, where the task is to classify whether one item in the pair should be ranked higher than the other. The classifier outputs the relative preference between two items, guiding the ranking order.
- Models
- RankNet
- Is a neural network-based pair-wise learning-to-rank algorithm developed by Microsoft.
- It learns to predict the relative ordering of item pairs by comparing them and minimizing a loss function that captures the difference in predicted relevance scores for the pairs.
- It uses a probabilistic cost function derived from the logistic function, where the probability that one item is ranked higher than another is modeled. This probabilistic model is trained using gradient descent to minimize the pair-wise ranking loss.
- RankNet’s architecture makes it particularly useful in capturing non-linear relationships between features, making it more versatile in complex ranking tasks.
- This model is effective at capturing complex, non-linear relationships between features, leading to improved ranking performance, End-to-End Differentiable using backpropagation thanks to neural network-based, flexibility: to change the architecture, and good performance for medium-sized data.
- But, As a neural network-based approach, it can be more computationally expensive and complex, it could affect slow convergence due to its reliance on gradient descent and non-linier optimization, and as neural network-based, it tend to be less interpretable.
- LambdaRank
- Is a widely used pair-wise ranking algorithm in information retrieval and recommender systems.
- It builds on gradient descent optimization to improve ranking metrics such as NDCG.
- This model adjusts the pairwise preference function, defined as the difference in relevance scores between two items, using a gradient-based approach.
- The gradient is calculated using the derivative of the ranking metric concerning the model parameters, guiding the updates in the model parameters to enhance the ranking metric.
- This model directly optimizes rangking metrics (i.e. NDCG), could handle large-scale data and request, and can be adapted to various pairwise preferences.
- But the implement can be complex comapared to point-wise methods, and can be resource-intensive expecially in training step.
- RankBoost
- Adapts boosting algorithms to learn a ranking function that minimizes pairwise mis-ranking errors.
- RankSVM
- Extends SVM to learn a ranking function by optimizing pairwise ranking constraints.
- LambdaMART
- RankNet
- Types
- single-item
- multi-item
- Pros
- Alignment with Ranking Tasks: Pair-wise methods naturally align with the goal of ranking, focusing on the relative order of items rather than absolute relevance scores.
- Improved Accuracy: By modeling pairwise preferences, these methods often provide more accurate rankings compared to point-wise approaches.
- Versatility: Pair-wise methods can be adapted to different ranking tasks and evaluation metrics, making them broadly applicable.
- Cons
- Need to generate pairs of items.
- Complexity: The need to evaluate and compare pairs can lead to increased computational complexity, especially for large datasets with many potential item pairs.
- Resource Intensity: Training pair-wise models can require significant computational resources and time, particularly when dealing with extensive query-item pairs.
List-wise Methods
- How
- By focus on optimizing the entire list of items rather than individual or pairs of items, List-wise methods treat the entire ranked list of items as a single unit and aim to optimize a scoring function that directly maps from the item set to a ranking score.
- List-wise methods can extend beyond binary or multiclass classification into learning complex ranking functions, where models are trained to directly optimize ranking metrics across an entire list, improving the overall ranking quality in contrast to just focusing on individual pairwise comparisons.
- Models
- Direct optimization of information retrieval (IR) measures, such as Normalized Discounted Cumulative Gain (NDCG):
- SoftRank
- AdaRank
- minimizing a loss function defined based on the unique properties of the target ranking:
- ListNet
- Algorithm that models the permutation probability of ranking orders.
- It leverages the softmax function to calculate the probability distribution over permutations of items, and the loss function is minimized based on the difference between the predicted and ground truth ranking distributions.
- This model directly optimizes ranking metrics, got holistic view due to evaluates the entire list, and flexible with different objective and architecture.
- But this model can be computational expensive and resource intensive particularly with large data or lists due to the need to calculate permutations, and can heavily depend on the quality of the input (sensitive to input features).
- ListMLE
- Maximum Likelihood Estimation approach that models the probability of the entire ranked list.
- LambdaMART
- is a highly scalable list-wise ranking algorithm that builds on the principles of LambdaRank (a pair-wise method) and combines it with Gradient Boosted Trees (GBTs).
- Optimizes ranking metrics such as NDCG by adjusting the pair-wise preference loss, but it does so in a list-wise fashion by focusing on the entire set of items within a query.
- This model effective for large-scale ranking tasks, gives high predictive performance, designed to scale efficiently to large data, focusing on directly optimizing ranking metrics, and Adaptable for Both Pair-wise and List-wise.
- But, despite its scalability, LambdaMART can still require substantial computational resources, has complexity in implementation and the performance can be heavily influenced by hyperparameter tuning.
- ListNet
- Direct optimization of information retrieval (IR) measures, such as Normalized Discounted Cumulative Gain (NDCG):
- Types
- single-item
- multi-item
- Pros
- Comprehensive Optimization: account for the entire list of items, leading to more holistic optimization of the ranking function.
- Direct Metric Alignment: such as NDCG.
- Enhanced Ranking Quality: By considering the entire list, list-wise methods can capture complex interdependencies between items, potentially leading to superior ranking accuracy.
- Cons
- Must include full ranking list
- Inherently more complex and computationally
- Resource-intensive for entire lists
- Implementation Challenges, expecially for custom cases.
Model architecture
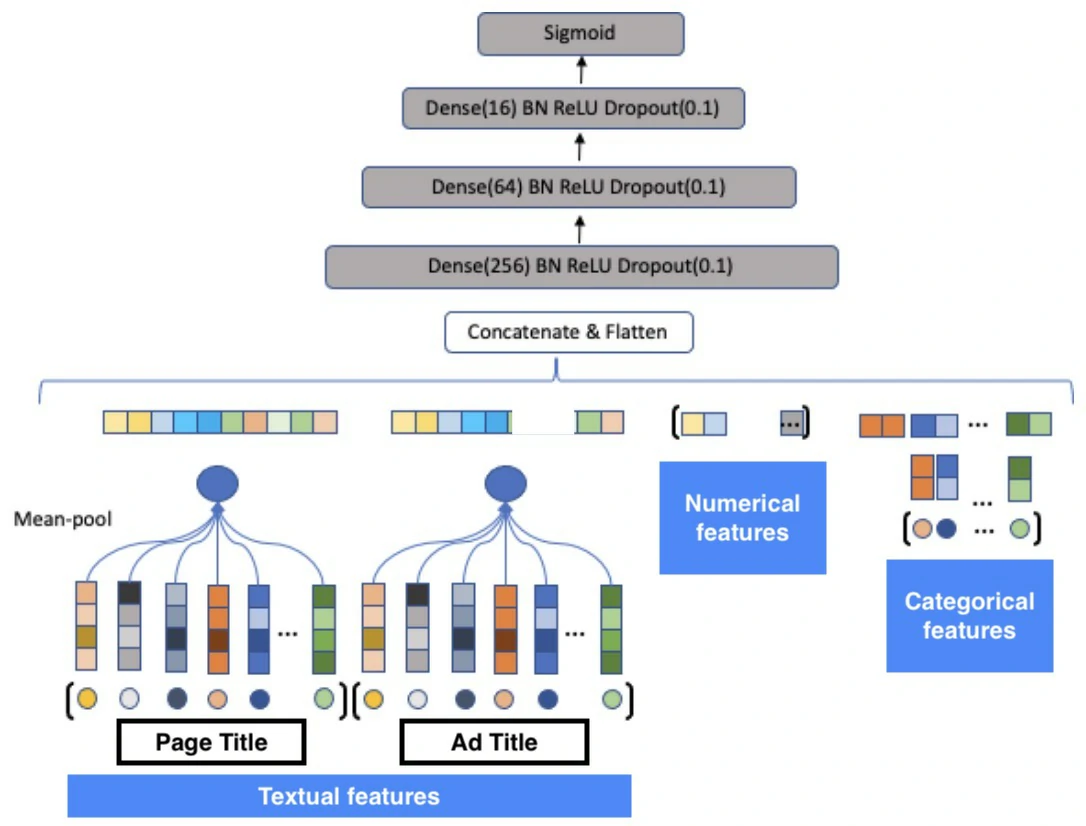
- CTR prediction for an ad on a page
- All the aforementioned features are concatenated and added as input to the MLP model with the click/non-click binary label and trained with binary cross entropy loss function.
- The textual features are converted to dense representation by:
- Tokenizing the input.
- Generating hash value for each token.
- Using the hash value to lookup corresponding embedding from the embedding table
- Performing mean-pool operation on the retrieved embedding vectors to generate a single dense representation for the text (e.g., the title of the product page).
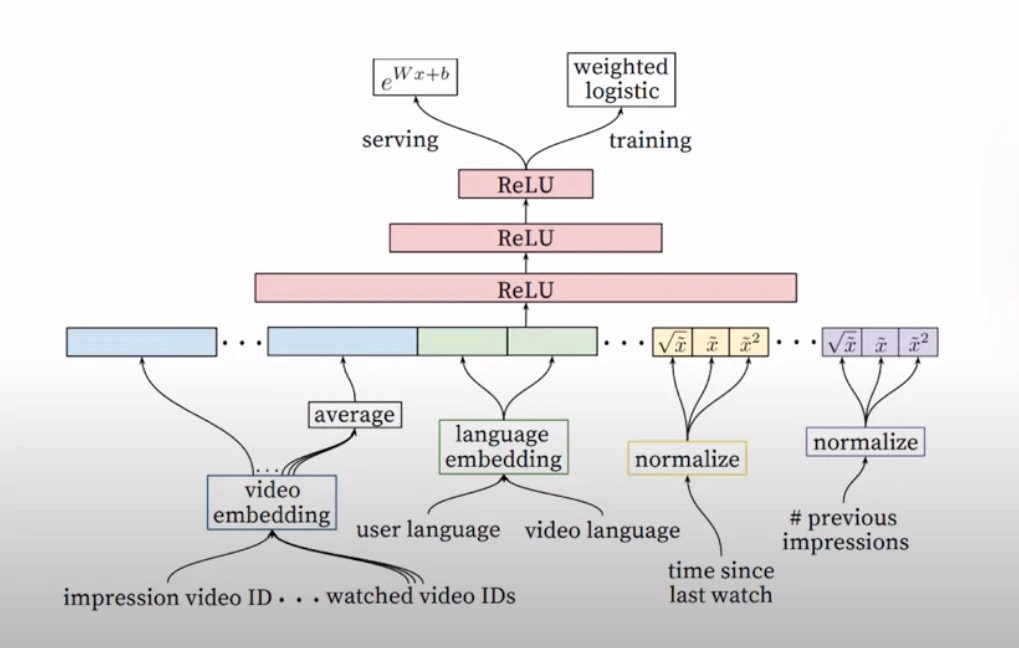
- YouTube Ranking
-
This architecture takes in 1 video and 1 user at one time and iterates this over all candidates but you could have multiple servers running this in parallel.
-