RAG - 101
LLM
rag
RAG (Retrieval-Augmented Generation)
- Combines information retrieval with a language model to generate accurate, relevant, less hallucination, private-secure and up-to-date answers.
RAG = Retrieval + Augmented + Generation- Instead of relying only on what the model was trained on, RAG lets the model look up information from trusted sources before generating a response.
- Retrieves more accurate, contextually appropriate, relevant data from a knowledge base
- Uses an LLM to generate a response based on that context
- RAG systems augment LLM model’s generative capabilities with real-time retrieval of information, ensuring responses are fluent, factually grounded, and relevant.
- Implementing RAG involves considerations such as the size of the context window and the need for data retrieval and storage in appropriate formats
- Core components:
- Embedding generator
- Retriever module
- Prompt Constructor
- Generator (LLM model)
Schema
RAG Pipeline
- Tech side
- Raw docs
- Document Processing
- Chunking
- add metadata
- Embedding generation each chunk
- Vectors and original text stored at each DB
- User side
- Query Processing
- Query Embedding
- Retrieval module
- Hybrid search (Similarity)
- Maximum Marginal Relevance (MMR)
- Top-k chunks
- BM25 Search (Top-30)
- Vector Search (Top-10)
- RRF Fusion (up to Top-40)
- Reranker
- Jina Cross-Encoder Scoring and top-10 Results
- Most Diverse
- Top-k chunks
- Context Formatting
- Organize with Metadata
- Apply instructions (format, tone, constraints)
- LLM model
What RAG system do:
- Chunk documents
- Turns documents into searchable vectors (embed chunks)
- Finds information using semantic search (retrive top-k chunks)
- Sends relevant context to the LLM
- Generates accurate answeres from the data
RAG type
| Type | Details | Examples |
|---|---|---|
| Standard | Basic retrieval + context for Q&A | answering questions from documents (fact-based Q&A, knowledge base assistants) |
| Fusion | multiple queries → better retrieval results | combining multiple retrieval strategies for better coverage (large-scale enterprise search) |
| Corrective | verifies queries or fixes responses | reducing hallucinations and fixing incorrect outputs (high-stakes domains like legal or healthcare) |
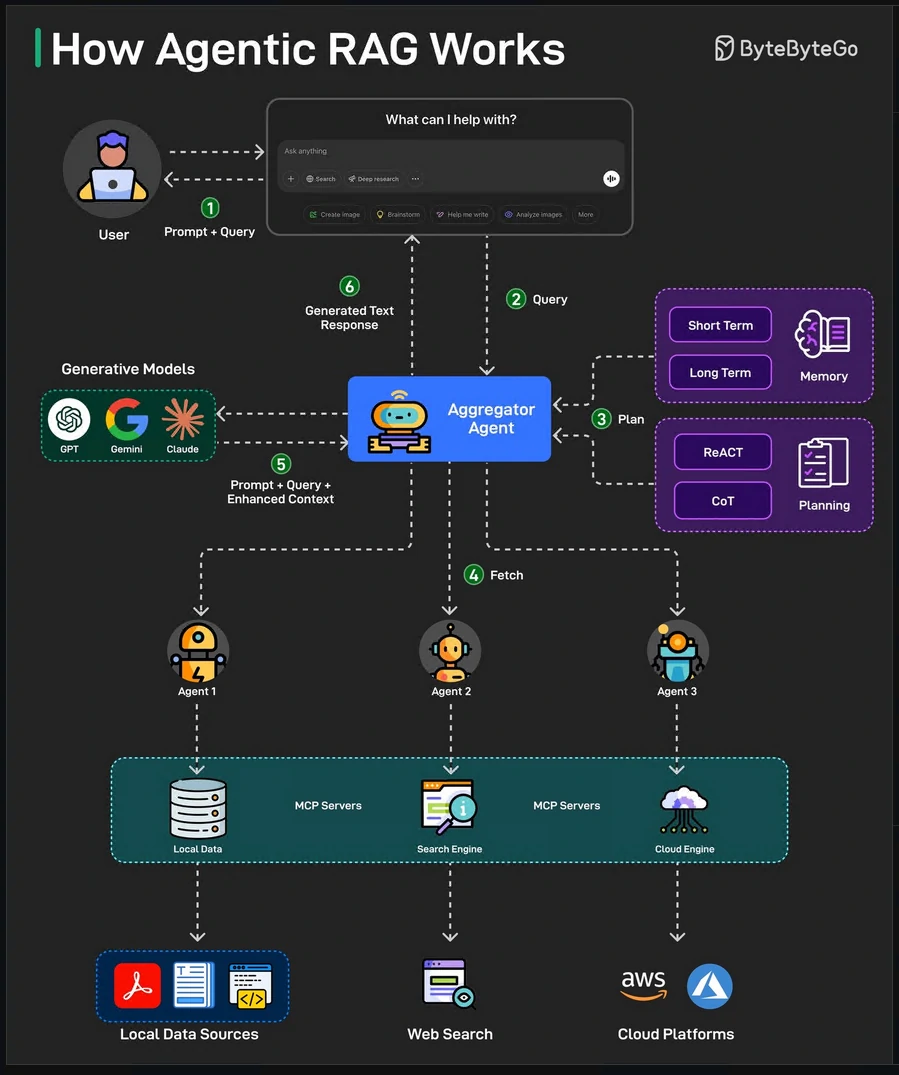
| Agentic | step-by-step reasoning loop with tools | automating workflows (research assistants, task automation, multi-step reasoning) |
| Modular | flexible pipeline (swap components) | building flexible systems that can be customized per use case (AI platforms, SaaS tools) |
| Multimodal | works with text, images, etc. | working with images, audio, and text together (medical reports, visual QA systems) |
| Graph | knowledge graph | understanding relationships in structured data (fraud detection, knowledge graphs), cross-document reasoning and multi-hop queries |
| Hybrid | combine between dense + sparse search and reranker | improving search accuracy in enterprise systems (BM/25 keyword - lexical search + semantic search) |
| Multi-query | handling vague or ambiguous user queries (customer support bots) | |
| Re-ranking | improving result quality in search engines and recommendation systems | |
| Adaptive | The system adaptively decides whether retrieval is needed based on the query type, and proceeds accordingly |
Techical
| Name | Details | Examples |
|---|---|---|
| Document crawler | - Scrapy ✅ - BeautifulSoup ✅ | |
| Document parsing | - PDF corpus | - pdfplumber ✅ - Docling ✅ - Crawler logic ✅ - Camelot - Tabula |
| Tokenization | Convert text into numerical or basic text as tokens | - SentencePiece - GPT’s BPE tokenizer |
| Embedding | - Convert the text into vectors - Converting text into vector representations - Captures the semantic meaning of the data - Make documents searchable using similiarity | - OpenAI - text-embedding-3-* - Azure OpenAI - DashScope - text-embedding-v3 - Bedrock - amazon.titan-embed-text-v2 - Vertex AI - text-embedding-005 - Voyage AI - voyage-3 - Cohere - embed-english-v3.0 - SiliconFlow - BAAI/bge-large-zh-v1.5 - Hugging Face - Any TEI-served model ✅ |
| VectorDB | - Pecific database to store vectors - Allows fast semantic search | - ChromaDB - Milvus ✅ - DynamoDB - OpenSearch - Qdrant - pgvector ✅ - Pinecone - Weaviate |
| Sematic Search | - FAISS ✅ | |
| Reranking Function | - Weighted Ranker ✅ - RRF Ranker ✅ - Boost Ranker ✅ - Decay Ranker ✅ - Model Ranker ✅ | |
| Reranking Model | - TEI ✅ - Cohere - Voyage AI - SiliconFlow | |
| LLM Model | - GPT - T5 ✅ - LLaMA ✅ - Falcon - Mistral ✅ - Phi ✅ - Gemini | |
| Model Alignment | - Supervised Fine-Tuning (SFT) - Reinforcement Learning from Human Feedback (RLHF) - Safety & Constitutional AI | - Train on high-quality human-annotated datasets (InstructGPT, Alpaca, Dolly) - Generate responses, rank outputs, train a Reward Model (PPO), and refine using Proximal Policy Optimization (PPO) - Apply RLAIF, adversarial training, and bias filtering |
| Model Optimization | - Compression & Quantization - API Serving & Scaling - Reduce model size with GPTQ, AWQ, LLM.int8(), and Knowledge Distillation - Deploy with vLLM, Triton Inference Server, TensorRT, ONNX, and Ray Serve for efficient inference | - FastAPI ✅ - vLLM ✅ |
| Model collection | - Hugging Face ✅ | |
| Pretraining | - Causal Language Modeling (CLM) with Cross-Entropy Loss - Gradient Checkpointing - Parallelization (FSDP, ZeRO) | |
| Optimizations | - Apply Mixed Precision (FP16/BF16) - Gradient Clipping - Adaptive Learning Rate Schedulers for efficiency | |
| Evaluation & Benchmarking | - Benchmarking performance - Red-Teaming - Adversarial Testing | - HumanEval - HELM - OpenAI Eval - MMLU - ARC - MT-Bench |
| Orchestrator | - Orchestrated conversation flow & intent detection | - LangChain ✅ - LangGraph ✅ - LangSmith - LlamaIndex ✅ - Ollama ✅ - vLLM ✅ - Azure AI Foundry |
| AI Agents | - Microsoft Autogen - Agno - OpenAI Agent Kit - CrewAI |
LLM Aided Retrieval - Optimizing RAG
- Chunking Strategy
- Hybrid Search: (combination of traditional keyword retrieval (BM25) + dense (vector-based) retrieval)
- Metadata Filtering: use tag, source, type, date, etc.
- Prompt Engineering
- Caching Results: speeds up repeated queries
- Multi-hop RAG: breaks complex queries into sub-questions and retrieves and reasons across RAG.
- Query rewriting: Improve vague user queries
- Self-RAG: Model checks its own output
- SelfQuery: where we use an LLM to convert the user question into a query.
- Core component: information » Query Parser » Search term + Filter
- Compression: Using LLM we could increase the number of results we can put in the context by shrinking the responses to only the relevant information.
RAG Optimization
- Everything starts with data quality.
- Poor chunking leads to:
- Too large → noisy, low precision
- Too small → missing context
- Hybrid search (semantic + keyword) becomes essential
- Re-ranking is critical to prioritize true relevance—not just similarity
- Enforce context. Too much information leads to the “lost in the middle” effect.
- LLMs may ignore retrieved context unless prompts enforce:
- Grounding
- Citations
- Context adherence
- Continuous feedback loops
- Performance monitoring
- Adaptive tuning to evolving data