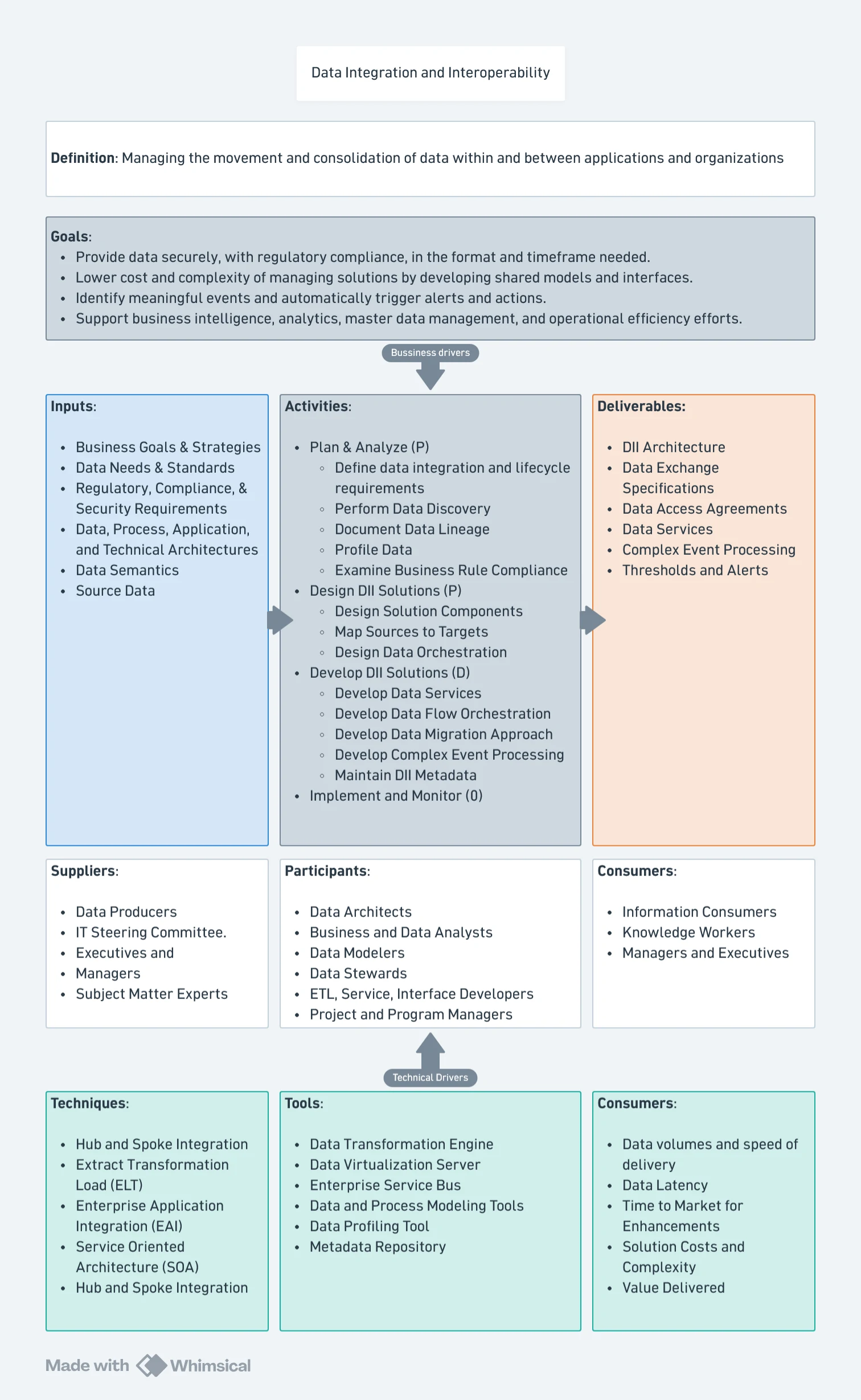
Data Integration and Interoperability
data Integration
data government
data management
- Data Integration and Interoperability
- Introduction
- Dependency
- Business Drivers
- Goals
- Principles
- Essential Concepts
- Interaction Models
- DII Architecture Concepts
- Application Coupling
- Orchestration and Process Controls
- Enterprise Application Integration (EAI)
- Enterprise Service Bus (ESB)
- Service-Oriented Architecture (SOA)
- Complex Event Processing (CEP)
- Data Federation and Virtualization
- Data-as-a-Service (DaaS)
- Cloud-based Integration
- Data Exchange Standards
- Data Integration Activities
- Plan and Analyze
- Design Data Integration Solutions
- Develop Data Integration Solutions
- Implement and Monitor
- Tools
- Techniques
- Implementation Guidelines
- Organization and Cultural Change
- DII Governance
- Data Sharing Agreements
- DII and Data Lineage
- Data Integration Metrics
Introduction
Data Integration and Interoperability (DII) describes processes related to the movement and consolidation of data within and between data stores, applications and organizations. Integration consolidates data into consistent forms, either physical or virtual. Data Interoperability is the ability for multiple systems to communicate.
Dependency
DII is dependent on these other areas of data management:
- Data Governance: For governing the transformation rules and message structures
- Data Architecture: For designing solutions
- Data Security: For ensuring solutions appropriately protect the security of data, whether it is persistent, virtual, or in motion between applications and organizations
- Metadata: For tracking the technical inventory of data (persistent, virtual, and in motion), the business meaning of the data, the business rules for transforming the data, and the operational history and lineage of the data.
- Data Storage and Operations: For managing the physical instantiation of the solutions
- Data Modeling and Design: For designing the data structures including physical persistence in databases, virtual data structures, and messages passing information between
Business Drivers
The need to manage data movement efficiently is a primary driver for DII.
An enterprise design of data integration is demonstrably more efficient and cost effective than distributed or point-to-point solutions. Developing point-to-point solutions between applications can result in thousands to millions of interfaces and can quickly overwhelm the capabilities of even the most effective and efficient IT support organization.
The complexity of managing operational and transactional data that needs to be shared across the organization can be greatly simplified using enterprise data integration techniques such as hub-and-spoke integration and canonical message models.
Standard tool implementations can reduce support and staffing costs and improve the efficiency of troubleshooting efforts. Reducing the complexity of interface management can lower the cost of interface maintenance, and allow support resources to be more effectively deployed on other organizational priorities.
Using Enterprise-level DII systems, give an:
- Ability to comply with data handling standards and regulations
- Enable re-use of code to implement compliance rules and simplify verification of compliance.
Goals
- Make data available in the format and timeframe needed by data consumers, both human and system.
- Consolidate data physically and virtually into data hubs
- Lower cost and complexity of managing solutions by developing shared models and interfaces
- Identify meaningful events (opportunities and threats) and automatically trigger alerts and actions.
- Support Business Intelligence, analytics, Master Data
- Management, and operational efficiency efforts
Principles
- Take an enterprise perspective in design to ensure future extensibility, but implement through iterative and incremental delivery
- Balance local data needs with enterprise data needs, including support and maintenance.
- Ensure business accountability for Data Integration and Interoperability design and activity. Business experts should be involved in the design and modification of data transformation rules, both persistent and virtual.
Essential Concepts
Extract, Transform, and Load
Central to all areas in Data Integration and Interoperability is the basic process of Extract, Transform, and Load (ETL).
- Periodically scheduled event (batch)
- Data needed for analysis or reporting is often scheduled in batch jobs.
- Whenever new or updated data is available (real-time or event-driven)
- Operational data processing tends to be real-time or near real-time.
Data integration requirements also determine whether the extracted and transformed data is physically stored in staging structures.
- Extract
- Extracted data is then staged, in a physical data store on disk or in memory. If physically staged on disk, the staging data store may be co-located with the source data store or with the target data store, or both.
- Transform
- Examples of transformation:
- Format changes
- Structure changes
- Semantic conversion
- De-duping
- Re-ordering
- Examples of transformation:
- Load
- The load step of ETL is physically storing or presenting the result of the transformations in the target system.
ELT
If the target system has more transformation capability than either the source or an intermediary application system, the order of processes maybe switched to ELT – Extract, Load, and Transform.
Mapping
A mapping defines the sources to be extracted, the rules for identifying data for extraction, targets to be loaded, rules for identifying target rows for update (if any), and any transformation rules or calculations to be applied.
Latency
Latency is the time difference between when data is generated in the source system and when the data is available for use in the target system.
Batch
Data moving in batch mode will represent either the full set of data at a given point in time, such as account balances at the end of a period, or data that has changed values since the last time the data was sent, such as address changes that have been made in a day. The set of changed data is called the delta, and the data from a point in time is called a snapshot.
To achieve fast processing and lower latency, some data integration solutions use micro-batch processing which schedules batch processing to run on a much higher frequency than daily, such as every five minutes.
There are risks associated with the timing of batch processing. To minimize issues with application updates, schedule data movement between applications at the end of logical processing for the business day, or after special processing of the data has occurred at night. To avoid incomplete data sets, jobs moving data to a data warehouse should be scheduled based on the daily, weekly, or monthly reporting schedule.
Change Data Capture
Change Data Capture is a method of reducing bandwidth by filtering to include only data that has been changed within a defined timeframe. Change data capture monitors a data set for changes (inserts, changes, deletes) and then passes those changes (the deltas) to other data sets, applications, and organizations that consume the data.
Data may also be tagged with identifiers such as flags or timestamps as part of the process. There are three techniques for databased change data capture:
- The source system populates specific data elements, such as timestamps within a range, or codes or flags, which serve as change indicators. The extract process uses rules to identify rows to extract.
- The source system processes add to a simple list of objects and identifiers when changing data, which is then used to control selection of data for extraction.
- The source system processes copy data that has changed into a separate object as part of the transaction, which is then used for extract processing.
In log-based change data captures, data activity logs created by the database management system are copied and processed, looking for specific changes that are then translated and applied to a target database.
Near-real-time and Event-driven
Data is processed in smaller sets spread across the day in a defined schedule, or data is processed when an event happens, such as a data update.
State information and process dependencies must be monitored by the target application load process.
Asynchronous
The system providing data does not wait for the receiving system to acknowledge update before continuing processing.
Synchronous data integration does not prevent the source application from continuing its processing, or cause the source application to be unavailable if any of the target applications are unavailable.
Real-time, Synchronous
When data in one data set must be kept perfectly in synch with the data in another data set, then a real-time, synchronous solution must be used.
This situation keeps data synchronized but has the potential to make strategic applications dependent on less critical applications.
Real-time, synchronous solutions require less state management than asynchronous solutions because the order in which transactions are processed is clearly managed by the updating applications.
Low Latency or Streaming
The extra costs of low latency solutions are justified if an organization requires extremely fast data movement across large distances. Low latency data integration solutions are designed to minimize the response time to events.
Asynchronous solutions are usually used in low latency solutions so that transactions do not need to wait for confirmation from subsequent processes before processing the next piece of data.
Massive multi-processing, or simultaneous processing, is also a common configuration in low latency solutions so that the processing of incoming data can be spread out over many processors simultaneously, and not bottlenecked by a single or small number of processors.
Replication
Replication solutions minimize the performance impact of analytics and queries on the primary transactional operating environment. Such a solution must synchronize the physically distributed data set copies.
Replication solutions usually monitor the log of changes to the data set, not the data set itself. They minimize the impact on any operational applications because they do not compete with the applications for access to the data set. Only data from the change log passes between replicated copies. Standard replication solutions are near-real-time; there is a small delay between a change in one copy of the data set and another.
Replication utilities work optimally when source and target data sets are exact copies of each other. Differences between source and target introduce risks to synchronization.
Data replication solutions are not optimal if changes to the data may occur at multiple copy sites. If it is possible that the same piece of data is changed at two different sites, then there is a risk that the data might get unsynchronized, or one of the sites may have their changes overwritten without warning.
Archiving
Data that is used infrequently or not actively used may be moved to an alternate data structure or storage solution that is less costly to the organization.
Use archives to store data from applications that are being retired, as well as data from production operational systems that have not been used for a long time, to improve operational efficiency.
It is critical to monitor archive technology to ensure that the data is still accessible when technology changes. Having an archive in an older structure or format unreadable by newer technology can be a risk, especially for data that is still legally required.
Enterprise Message Format / Canonical Model
A canonical data model is a common model used by an organization or data exchange group that standardizes the format in which data will be shared. In a hub-and-spoke data interaction design pattern, all systems that want to provide or receive data interact only with a central information hub. Data is transformed from or to a sending or receiving system based on a common or enterprise message format for the organization.
Although developing and agreeing on a shared message format is a major undertaking, having a canonical model can significantly reduce the complexity of data interoperability in an enterprise, and thus greatly lower the cost of support.
Interaction Models
Interaction models describe ways to make connections between systems in order to transfer data.
Point-to-point
Point-to-point - they pass data directly to each other. It becomes quickly inefficient and increases organizational risk when many systems require the same data from the same sources.
- Impacts to processing: If source systems are operational, then the workload from supplying data could affect processing.
- Managing interfaces: The number of interfaces needed in a point-to-point interaction model approaches the number of systems squared (s^2) for need to be maintained and supported.
- Potential for inconsistency: Design issues arise when multiple systems require different versions or formats of the data.
Hub-and-spoke
The hub-and-spoke model, consolidates shared data (either physically or virtually) in a central data hub that many applications can use. All systems that want to exchange data do so through a central common data control system, rather than directly with one another (point-to-point). Data Warehouses, Data Marts, Operational Data Stores, and Master Data Management hubs are the most well-known examples of data hubs.
The hubs provide consistent views of the data with limited performance impact on the source systems. Data hubs even minimize the number of systems and extracts that must access the data sources, thus minimizing the impact on the source system resources. Adding new systems to the portfolio only requires building interfaces to the data hub.
Some hub-and-spoke model latency is unacceptable or performance is insufficient. The benefits of the hub outweigh the drawbacks of the overhead as soon as three or more systems are involved in sharing data.
Publish-Subscribe
A publish and subscribe model involves systems pushing data out (publish), and other systems pulling data in (subscribe).
When multiple data consumers want a certain set of data or data in a certain format, developing that data set centrally and making it available to all who need it ensures that all constituents receive a consistent data set in a timely manner.
DII Architecture Concepts
Application Coupling
Coupling describes the degree to which two systems are entwined. Two systems that are tightly coupled usually have a synchronous interface, where one system waits for a response from the other. Tight coupling represents a riskier operation: if one system is unavailable then they are both effectively unavailable, and the business continuity plan for both have to be the same.
Loose coupling is a preferred interface design, where data is passed between systems without waiting for a response and one system may be unavailable without causing the other to be unavailable.
Where the systems are loosely coupled, replacement of systems in the application inventory can theoretically be performed without rewriting the systems with which they interact, because the interaction points are welldefined.
Orchestration and Process Controls
Orchestration is the term used to describe how multiple processes are organized and executed in a system.
Process Controls are the components that ensure shipment, delivery, extraction, and loading of data is accurate and complete.
Aspect of basic data movement architecture, controls include:
- Database activity logs
- Batch job logs
- Alerts
- Exception logs
- Job dependence charts with remediation options, standard responses
- Job ‘clock’ information
Enterprise Application Integration (EAI)
Enterprise application integration model (EAI), software modules interact with one another only through well-defined interface calls (application programming interfaces – APIs).
Other software cannot reach in to the data in an application but only access through the defined APIs. EAI is built on object-oriented concepts, which emphasize reuse and the ability to replace any module without impact on any other.
Enterprise Service Bus (ESB)
An Enterprise Service Bus is a system that acts as an intermediary between systems, passing messages between them. Applications can send and receive messages or files using the ESB, and are encapsulated from other processes existing on the ESB.
Service-Oriented Architecture (SOA)
Service-oriented architecture (SOA), where the functionality of providing data or updating data (or other data services) can be provided through well-defined service calls between applications.
Applications do not have to have direct interaction with or knowledge of the inner workings of other applications.
SOA enables application independence and the ability for an organization to replace systems without needing to make significant changes to the systems that interfaced with them.
The goal of service-oriented architecture is to have well-defined interaction between self-contained software modules.
The key concept is that SOA architecture provides independent services: the service has no fore knowledge of the calling application and the implementation of the service is a black box to the calling application. A service-oriented architecture may be implemented with various technologies including web services, messaging, RESTful APIs, etc.
Well-defined API registry describes what options are available, parameters that need to be provided, and resulting information that is provided.
Data services, which may include the addition, deletion, update, and retrieval of data, are specified in a catalog of available services. To achieve the enterprise goals of scalability (supporting integrations between all applications in the enterprise without using unreasonable amounts of resources to do so) and reuse (having services that are leveraged by all requestors of data of a type), a strong governance model must be established around the design and registration of services and APIs.
Ensure that no service already exists that could provide the requested data.
New services need to be designed to meet broad requirements so that they will not be limited to the immediate need but can be reused.
Complex Event Processing (CEP)
Event processing is a method of tracking and analyzing (processing) streams of information (data) about things that happen (events), and deriving a conclusion from them. Complex event processing (CEP) combines data from multiple sources to identify meaningful events (such as opportunities or threats) to predict behavior or activity and automatically trigger real-time response, such as suggesting a product for a consumer to purchase.
Organizations can use complex event processing to predict behavior or activity and automatically trigger real-time response.
An event may also be defined as a change of state, when a measurement exceeds a predefined threshold of time, temperature, or other value.
Efficient processing typically mandates pre-positioning some data in the CEP engine’s memory.
Data Federation and Virtualization
Data Federation provides access to a combination of individual data stores, regardless of structure. Data Virtualization enables distributed databases, as well as multiple heterogeneous data stores, to be accessed and viewed as a single database.
Data-as-a-Service (DaaS)
Data-as-a-Service (DaaS) is data licensed from a vendor and provided on demand, rather than stored and maintained in the data center of the licensing organization.
Although Data-as-a-Service certainly lends itself to vendors that sell data to stakeholders within an industry, the ‘service’ concept is also used within an organization to provide enterprise data or data services to various functions and operational systems.
Cloud-based Integration
Cloud-based integration (also known as integration platform-as-a-service or IPaaS) is a form of systems integration delivered as a cloud service that addresses data, process, service oriented architecture (SOA), and application integration use cases.
Internal integration requirements are serviced through an on-premises middleware platform, and typically use a service bus (ESB) to manage exchange of data between systems. Business-to-business integration is serviced through EDI (electronic data interchange) gateways or value-added networks (VAN) or market places.
Data Exchange Standards
Data Exchange Standards are formal rules for the structure of data elements. A data exchange specification is a common model used by an organization or data exchange group that standardizes the format in which data will be shared.
Although developing and agreeing on a shared message format is a major undertaking, having an agreed upon exchange format or data layout between systems can significantly simplify data interoperability in an enterprise, lowering the cost of support and enabling better understanding of the data.
Data Integration Activities
Data Integration and Interoperability involves getting data where it is needed, when it is needed, and in the form in which it is needed. Data integration activities follow a development lifecycle. They begin with planning and move through design, development, testing, and implementation. Once implemented, integrated systems must be managed, monitored and enhanced.
Plan and Analyze
Define Data Integration and Lifecycle Requirements
- Defining data integration requirements involves understanding the organization’s business objectives, as well as the data required and the technology initiatives proposed to meet those objectives.
- Gather any relevant laws or regulations regarding the data to be used.
- Some activities may need to be restricted due to the data contents, and knowing up front will prevent issues later.
- Account for organizational policy on data retention and other parts of the data lifecycle.
The requirements will determine the type of DII interaction model, which then determines the technology and services necessary to fulfill the requirements.
The process of defining requirements creates and uncovers valuable Metadata. This Metadata should be managed throughout the data lifecycle, from discovery through operations.
Perform Data Discovery
Data discovery should be performed prior to design. The goal of data discovery is to identify potential sources of data for the data integration effort. Discovery will identify where data might be acquired and where it might be integrated.
Discovery also includes high-level assessment of data quality, to determine whether the data is fit for the purposes of the integration initiative.
In almost all cases, there will be discrepancies between what is believed about a data set and what is actually found to be true.
Maintained as a standard part of integration efforts: add or remove data stores, document structure changes.
Document Data Lineage
The process of data discovery will also uncover information about how data flows through an organization. This information can be used to document high-level data lineage: how the data under analysis is acquired or created by the organization, where it moves and is changed within the organization, and how the data is used by the organization for analytics, decision-making, or event triggering.
Custom-coded ETL and other legacy data manipulation objects should be documented to ensure that the organization can analyze the impact of any changes in the data flow.
The analysis process may also identify opportunities for improvements in the existing data flow.
Profile Data
Actual data structure and contents always differ from what is assumed.
Profiling can help integration teams discover these differences and use that knowledge to make better decisions about sourcing and design.
Basic profiling involves analysis of:
- Data format as defined in the data structures and inferred from the actual data
- Data population, including the levels of null, blank, or defaulted data
- Data values and how closely they correspond to a defined set of valid values
- Patterns and relationships internal to the data set, such as related fields and cardinality rules
- Relationships to other data sets
Understand how well the data meets the requirements of the particular data integration initiative. Profile both the sources and targets to understand how to transform the data to match requirements.
One goal of profiling is to assess the quality of data. Assessing the fitness of the data for a particular use requires documenting business rules and measuring how well the data meets those business rules.
Capture results of data profiling in a Metadata repository for use on later projects and use what is learned from the process to improve the accuracy of existing Metadata.
Collect Business Rules
A business rule is a statement that defines or constrains an aspect of business processing. Business rules are intended to assert business structure or to control or influence the behavior of the business.
Business rules fall into one of four categories:
- definitions of business terms,
- facts relating terms to each other,
- constraints or action assertions,
- derivations.
Use business rules to support Data Integration and Interoperability at various points, to:
- Assess data in potential source and target data sets
- Direct the flow of data in the organization
- Monitor the organization’s operational data
- Direct when to automatically trigger events and alerts
For Master Data Management, business rules include match rules, merge rules, survivorship rules, and trust rules. For data archiving, data warehousing, and other situations where a data store is in use, the business rules also include data retention rules.
Gathering business rules is also called rules harvesting or business rule mining.
Design Data Integration Solutions
By establishing enterprise standards, the organization saves time in implementing individual solutions, because assessments and negotiations have been performed in advance of need.
It will include an inventory of the involved data structures (both persistent and transitive, existing and required), an indication of the orchestration and frequency of data flow, regulatory and security concerns and remediation, and operating concerns around backup and recovery, availability, and data archive and retention.
Select Interaction Model
Hub-and-spoke, point-to-point, or publish-subscribe. If the requirements match an existing interaction pattern already implemented, re-use the existing system as much as possible, to reduce development efforts.
Design Data Services or Exchange Patterns
Be careful to not create multiple almost-identical services, as troubleshooting and support increasingly become difficult if services proliferate.
Any data exchange specification design should start with industry standards, or other exchange patterns already existing. Make any changes to existing patterns generic enough to be useful to other systems; having specific exchange patterns that only relate to one exchange has the same issues as point-to-point connections.
Model Data Hubs, Interfaces, Messages, and Data Services
Data structures needed in Data Integration and Interoperability include those in which data persists, such as Master Data Management hubs, data warehouses and marts, and operational data stores, and those that are transient and used only for moving or transforming data, such as interfaces, message layouts, and canonical models. Both types should be modeled.
Map Data Sources to Targets
Mapping sources to targets involves specifying the rules for transforming data from one location and format to another.
For each attribute mapped, a mapping specification:
- Indicates the technical format of the source and target
- Specifies transformations required for all intermediate staging points between source and target
- Describes how each attribute in a final or intermediate target data store will be populated
- Describes whether data values need to be transformed; for example, by looking up the source value in a table that indicates the appropriate target value
- Describes what calculations are required
Transformation may be performed on a batch schedule, or triggered by the occurrence of a real-time event. It may be accomplished through physical persistence of the target format or through virtual presentation of the data in the target format.
Design Data Orchestration
The flow of data in a data integration solution must be designed and documented. Data orchestration is the pattern of data flows from start to finish, including intermediate steps, required to complete the transformation and/or transaction.
Develop Data Integration Solutions
Develop services to access, transform, and deliver data as specified, matching the interaction model selected.
Develop Data Flows
Integration or ETL data flows will usually be developed within tools specialized to manage those flows in a proprietary way. Batch data flows will be developed in a scheduler.
Interoperability requirements may include developing mappings or coordination points between data stores.
Developing real-time data integration flows involves monitoring for events that should trigger the execution of services to acquire, transform, or publish data.
Develop Data Migration Approach
This process involves transformation of data to the format of the receiving application. Migration is not quite a onetime process, as it needs to be executed for testing phases as well as final implementation.
Data migration do not engage in the analysis and design activities required for data integration. When data is migrated without proper analysis, it often looks different from the data that came in through the normal processing.
Profiling data of core operational applications will usually highlight data that has been migrated from one or more generations of previous operational systems and does not meet the standards of the data that enters the data set through the current application code.
Develop Complex Event Processing Flows
Developing complex event processing solutions requires:
- Preparation of the historical data about an individual, organization, product, or market and pre-population of the predictive models
- Processing the real-time data stream to fully populate the predictive model and identify meaningful events (opportunities or threats)
- Executing the triggered action in response to the prediction
Maintain DII Metadata
This Metadata should be managed and maintained to ensure proper understanding of the data in the system, and to prevent the need to rediscover it for future solutions. Reliable Metadata improves an organization’s ability to manage risks, reduce costs, and obtain more value from its data.
Document the data structures of all systems involved in data integration as source, target, or staging. Include business definitions and technical definitions (structure, format, size), as well as the transformation of data between the persistent data stores. It should not be changed without a review and approval process from both business and technical stakeholders.
If the Metadata repository is utilized as an operational tool, then it may even include operational Metadata about when data was copied and transformed between systems.
Implement and Monitor
Establish parameters that indicate potential problems with processing, as well as direct notification of issues. Automated as well as human monitoring for ssues should be established, especially as the complexity and risk of the triggered responses rises.
Tools
Data Transformation Engine/ETL Tool
Data Virtualization Server
Data transformation engines usually perform extract, transform, and load physically on data; however, data virtualization servers perform data extract, transform, and integrate virtually.
Enterprise Service Bus
An enterprise service bus (ESB) refers to both a software architecture model and a type of message-oriented middleware used to implement near real-time messaging between heterogeneous data stores, applications, and servers that reside within the same organization.
The enterprise service bus implements incoming and outgoing message queues on each of the systems participating in message interchange with an adapter or agent installed in each environment. The central processor for the ESB is usually implemented on a server separate from the other.
Business Rules Engine
Many data integration solutions are dependent on business rules. An important form of Metadata, these rules can be used in basic integration and in solutions that incorporate complex event processing to enable an organization to respond to events in near real-time.
Data and Process Modeling Tools
Data Profiling Tool
Data profiling involves statistical analysis of data set contents to understand format, completeness, consistency, validity, and structure of the data. All data integration and interoperability development should include detailed assessment of potential data sources and targets to determine whether the actual data meets the needs of the proposed solution.
Metadata Repository
A Metadata repository contains information about the data in an organization, including data structure, content, and the business rules for managing the data. the rules regarding data transformation, lineage, and processing used by the data integration tools are also stored in a Metadata repository as are the instructions for scheduled processes such as triggers and frequency.
Techniques
The basic goals are to keep the applications coupled loosely, limit the number of interfaces developed and requiring management by using a hub-and-spoke approach, and to create standard (or canonical) interfaces.
Implementation Guidelines
Readiness Assessment / Risk Assessment
Focus on implementing data integration solutions where none or limited integration currently exists, rather than replacing working data integration solutions with a common enterprise solution across the organization.
It is necessary to sponsor the implementation of an enterprise data integration program from a level that has sufficient authority over solution design and technology purchase, such as from IT enterprise architecture. In addition, it may be necessary to encourage application systems to participate through positive incentives, such as funding the data integration technology centrally, and through negative incentives, such as refusing to approve the implementation of new alternative data integration technologies.
Making sure that some participants in every project are businessor application-oriented, and not just data integration tool experts.
Organization and Cultural Change
Develop a Center of Excellence specializing in the design and deployment of the enterprise data integration solutions. Local and central teams collaborate to develop solutions connecting an application into an enterprise data integration solution.
DII Governance
Decisions about the design of data messages, data models, and data transformation rules have a direct impact on an organization’s ability to use its data. These decisions must be business-driven.
Business stakeholders are responsible for defining rules for how data should be modeled and transformed. Business stakeholders should approve changes to any of these business rules. Rules should be captured as Metadata and consolidated for cross-enterprise analysis.
One approach is to determine what events trigger governance reviews (exceptions or critical events). Map each trigger to reviews that engage with governance bodies. Event triggers may be part of the System Development Life Cycle (SDLC) at Stage Gates when moving from one phase to another or as part of User Stories.
Controls may come from governance-driven management routines, such as mandated reviews of models, auditing of Metadata, gating of deliverables, and required approvals for changes to transformation rules.
In Service Level Agreements, and in Business Continuity/Disaster Recovery plans, real-time operational data integration solutions must be included in the same backup and recovery tier as the most critical system to which they provide data.
Policies need to be established to ensure that the organization benefits from an enterprise approach to DII.
Data Sharing Agreements
Develop a data sharing agreement or memorandum of understanding (MOU) which stipulates the responsibilities and acceptable use of data to be exchanged, approved by the business data stewards of the data in question. The data sharing agreements should specify anticipated use and access to the data, restrictions on use, as well as expected service levels, including required system up times and response times. These agreements are especially critical for regulated industries, or when personal or secure information is involved.
DII and Data Lineage
Governance is required to ensure that knowledge of data origins and movement is documented. Data sharing agreements may stipulate limitations to the uses of data and in order to abide by these, it is necessary to know where data moves and persists.
Describe where their data originated and how it has been changed as it has moved through various systems.
Forward and backward data lineage (i.e., where did data get used and where did it come from) is critical as part of the impact analysis needed when making changes to data structures, data flows, or data processing.
Data Integration Metrics
To measure the scale and benefits from implementing Data Integration solutions:
- Data Availability
- Data Volumes and Speed
- Volumes of data transported and transformed
- Volumes of data analyzed
- Speed of transmission
- Latency between data update and availability
- Latency between event and triggered action
- Time to availability of new data sources
- Solution Costs and Complexity
- Cost of developing and managing solutions
- Ease of acquiring new data
- Complexity of solutions and operations
- Number of systems using data integration solutions